Chapter 4 Dealing with Data
## Warning: package 'knitr' was built under R version 3.4.3Figure 4.1: The research cycle involves many seemingly seperate skills, from reading the literature and brainstorm- ing a new idea, designing and running and experiment, analyzing the data, writing and submitting a paper, navi- gating the review process, and starting again on the next project.
4.1 Data
4.1.1 Experiments are data machines
Researchers create experiments to answer questions. Ideally, the literature has been consulted to define a well-formed question that has not yet been addressed by the literature. Identifying a gap in current knowledge motivates the need to pursue the question, because providing an answer would contribute new knowledge to the field.
Figure 4.2: The research cycle can also be viewed as a series of transformations of data. Good questions are those that can be answered with data, so the question itself is one that implies data of a certain type. The ideal data is transformed again into real data as the experiment is designed and run. The observed raw data is transformed again through statistical analysis. Finally, the data is transformed again into meaningful numbers, words and pictures when it is communicated to a larger audience.
The process of answering the question involves conducting an experiment. Ideally, the question has at least two plausible answers, and the experimenter can create a suitable design to test predictions made by either answer. The predictions are tested by analyzing the results of the experiment. Other times a research has an exploratory question and creates an experiment to measure a new phenomena of interest.
Data is needed to answer questions, and experiments are conducted to produce the needed data. Experiments are data creation machines, and computer programming is a tool to create the machine. The experiment machine is part of the assembly line in the experimenters data-creation factory.
Consider a crayon factory. The goal of the factory is to create and sell crayons. The factory takes in raw materials, transforms and combines them, and outputs boxes of crayons. The entire process from beginning to end is focused on the end goal of making a high-quality and standardized box of crayons that children around the world can rely on for their drawings.
Experiments are similar. They take in subjects as raw materials, transform the subject into quantifiable measures of behavior in different experimental conditions, and output a data file recording the events of the experiment. The entire process is focused on the end goal of producing data that can be analyzed to address the research question. Experiments begin with a need for data, they are conducted to produce the data, and they end with an analysis and report of the data. Research is the skill of producing, analyzing, and communicating data.
4.1.2 What is Data?
Data is information that we possess about the world around us. For practical purposes, we will consider data as records of measurements that have been taken and the conditions in which those measurements were taken. In Psychology there are numerous measurements: reaction times, accuracy, likert scales, physiological responses, emotional responses, vocal responses, written responses, electrophysiological recordings, to list a few. Regardless of content, the most important feature of data that makes it useful is organization. Data that can be organized can be submitted to analysis and described and communicated in meaningful ways to produce knowledge.
Organization is important for the production and analysis of data. During production, choices are made that determine which events of an experiment are recorded (the content), and how they are stored (the format). A typical experiment has independent variables of interest (what is manipulated) and dependent variables of interest (what is measured). The data should minimally provide records of each. The record of content should be precise enough to allow the researcher to reconstruct the sequences of events of interest that took place during the experiment. The format of the data should be organized so that any event of interest from the experiment can be retrieved with precision from the record. There are many ways to format data, and we will be introduced to some of them in due course.
Figure 4.3: Example raw data with each line showing the trial number, condition, reaction time, and accuracy coded as a 0 or 1.
During analysis the raw data is already in hand. Raw data is often lengthy, bulky, and seemingly complex. Imagine conducting an experiment with one hundred subjects that measured reaction times in 2 conditions with 1000 trials each. The raw-data could be 100 individual text files each containing 2000 lines of text, with each line coding measurements taken on each trial. The experimenter might want to know if reaction times were faster in condition one than condition two. The raw-data holds the answer to this question, but does not provide the answer. Instead, the raw-data must be summarized and submitted to statistical analysis. For example, one might find the mean reaction times for each subject in each condition. This would be 100 mean reaction times in condition 1, and 100 reaction times in condition 2. From this point, a t-test could be used to determine if there were any significant differences between the conditions. Moving from the raw-data to the t-test requires transformation of the raw-data, which codes performance on individual trials, to estimates of mean performance in each condition across trials. Computer programming techniques can be used to make the transformation fairly effortless. However, the amount of pre-processing (or getting the data ready for analysis) can depend on how the data is formatted in the first place.
4.1.3 Practical issues with data in Psychology
Handling raw data. Data from exper- iments come in many formats. There are some standard formats, however each experiment builder program will preserve the data in different ways, and if the researcher creates their own experiment, they will make their own, possibly idiosyncratic, choices about how to preserve their data. Usually the raw data is not formatted in a way to allow statistical software programs to immediately analyze the measurements of interest. Thus, the raw data must be transformed, and formatted in a new way that is acceptable to the statistical software.
Corrupted data. Data files often are not always uniform. They may contain special characters, missing numbers, extra numbers, missing subjects, outly- ing data points, and so on. Researchers need to be aware of these possibilities to properly filter their data in order to obtain a meaningful analysis.
Data-sharing. It is not uncommon to ask another researcher for their raw data, or for another researcher to ask you for your data. Your data should be formatted in way that can be shared, which means that your organizational strategy for storing the data should be sensible and communicable. The data you receive from another person may not be formatted in a familiar manner. Data-analysis skill requires that you should be flexible and capable of transforming unfamiliar data formats into formats that can be analyzed by you.
Data-exploration. Data often holds insights that were not part of a planned analysis. Skill in data-analysis requires the ability to make new and creative transformations of the data to answer exploratory questions.
As the saying goes, the devil is in the details. One of the most devilish and annoying problems is dealing with data-formatting issues. The issue often becomes most apparent during data analysis. For example, consider the student who has just finished running their first experiment. Like the example above, they now possess tens or hundreds of files coding the experimental events for every subject. Let’s imagine the next step is to find individual means for each subject in each condition. If the student does not know basic programming techniques how should they proceed? The most tedious approach would be to open each individual data-file, and calculate by hand the means for each condition. This quickly becomes extremely onerous, and is highly prone to human error. Another student might instead use a spreadsheet program to speed some of the calculations. Even here the format of the data can be a problem. For example, what should the student do if they can’t figure out how to load the raw-data into the spreadsheet? Depending on how the raw data is stored, it may copy easily into the spreadsheet, or it may not. After the means are calculated it is usually necessary to conduct inferential statistical tests. Here again, different statistical software packages require the means to formatted in different ways for the program to complete the analysis. Without basic computer programming techniques, the student may have to reformat the data by hand. Formatting data by hand is a valuable experience, because it invites a closer look at the formatting and data itself. But, it quickly becomes tedious, time-consuming, and is prone to human error.
Even when computer programming techniques are applied to data-analysis, the devil remains in the formatting, and here even more so. This is because programming languages are extremely literal, and if the script used to analyze the data does not follow the format precisely it will fail. In addition, programming language themselves are detail oriented and store data in different formats. So, applying computer programming techniques requires familiarity with the format of the data, the format of how the program stores the data, and algorithms for transforming data between formats.
By hand or by programming, dealing with data requires the drudgery of dealing with it’s format. Learning to solve these problems with programming is valuable because it allows the process to be automated (saving time), and transparent (errors can be identified and fixed).
4.1.4 Data Transformation Skills
Research is the skill of producing, analyzing, and communicating data. Acquiring expertise in research skills unfolds in the same way that expertise is acquired in other domains like music, sport, and the arts: with lots of deliberate practice. In other skilled domains, performers practice specific components of their skill. So, it is helpful to outline important components of research skills that should be practiced.
4.1.4.0.1 Producing Data
Figure 4.4: Producing Data
Learning how to save the data that you are interested in analyzing is an important skill. Sometimes the decisions about what is recorded and how it is recorded are made by the program used to run the experiment. If you did not make the program to run the experiment, then you may not be free to choose how the data will be stored. This restriction can become apparent when attempting to run more complicated designs than allowed by the experiment builder program. Most builder programs allow scripting, which can serve to modify how the experiments runs and how the data is saved. Learning how to program a experiment from scratch is also insightful. It requires the programmer to make explicit decisions about the storage of experimental events. These decisions become important later on because the simplicity of analyzing the data can depend on the format in which it is stored.
4.1.4.0.2 Pre-Processing Data
Figure 4.5: Pre-processsing
In the next section we will look at a few different standard formats commonly used to store data. Often times it is necessary to convert from one format to another prior to analyzing the data with statistics software (or with your own scripts). These transformations can be easily accomplished with computer programming techniques. An important skill is to be comfortable with receiving data in any format, and converting it to a preferred and familiar format that is comfortable to work with. Pre-processing can be a tedious step, so learning this skill can lead to major savings in time down the road.
4.1.4.0.3 Analyzing Data
Figure 4.6: Analyzing
The number of ways in which raw-data can be transformed and submitted to statistical analysis is way beyond the scope of this guide. Some common transformation are finding means for each condition for each subject, and then doing inferential statistics on those means. Programming languages like R can be used to accomplish both of these transformations in a couple lines of code. R can also be used to explore data in endless and exciting ways.
4.1.4.0.4 Communicating Data
Figure 4.7: Communicating
Ultimately, the data collected from a successful research project will be written up, submitted, and accepted for publication. Most journals have standards for figures and graphs showing patterns of data. So, another important skill is learning how to produce journal-quality figures. There are many ways to accomplish this goal. The programming language R again provides many powerful tools for creating journal-quality figures.
4.2 Standard Data Formats
There are many ways that data can be formatted to preserve the same information. Two common standards are known as wide and long format. Both formats can be used to preserve the same kind of information. Consider a simple data set involving mean accuracy scores for each subject in two conditions.
4.2.0.0.1 Wide Format
Figure 4.8: Wide format
Wide format data involves a table or matrix of information, involving rows and columns. Each line or row in this example represents means from an individual subject. The columns represent means from each condition. With this format, the data for any subject in any condition can be found by searching through the table and finding the appropriate row and column corresponding to the subject and condition of interest.
4.2.0.0.2 Long Format
Figure 4.9: Long Format
Long format data again uses a table or matrix of information, involving rows and columns. The first column codes the subject number, the second column codes mean accuracy, and the third column codes the experimental condition. Notice, that each subject has two lines in this format, one for each measurement of the dependent variable (accuracy) for each level of the independent variable (condition). As with the wide format, the data for any subject in any condition can be found by searching through the table and finding the appropriate subject number, condition, and mean. Long-format has more lines than wide-format, hence the name.
4.2.0.0.3 Practical importance of format
Wide and long format are formally equivalent, they both preserve the same information about the data, and one is not necessarily better than the other. Depending on the amount of data, wide-format can often be more useful than long because the entire data-set may be visualized on a single screen.
Figure 4.10: Analysis steps
Data format can become an issue when using statistical software packages, as the program may demand that the data be formatted in a particular way for a particular statistical test. For example, wide-format can be used in SPSS for repeated-measures ANOVAs, but long-format is used for between-subjects ANOVAs, and a combination of formats is used for mixed design ANOVAs. In R, many of the statistics packages require the data to be in long-format. It is important to become comfortable with either format, and with techniques for transforming data between formats.
4.3 Examples Using Excel
So far we have not discussed many concrete examples of data, or of techniques for transforming it. One tried and true method for getting a feel for the problem is to work with data in a spreadsheet program, such as Microsoft Excel. Ultimately, we will be moving away from these methods, but they are nevertheless an important tool, and can often solve problems very quickly without the need for more complicated programming techniques. Last, working with data in a spreadsheet program will develop your sense of where important features of the data are located, and the operations that must be conducted on the data in order to transform it into a desired state.
4.3.1 A simple detection experiment
Consider a simple detection experiment with 20 subjects. In this experiment, subjects practice responding the onset of an X as quickly as possible. On each trial, the subject sees a fixation cross providing a warning that a stimulus is about to appear, then they wait for a short or long delay before the X appears. The short delay is 100 ms, and the long delay is 500 ms. There are 100 trials in each condition. Typically, in this sort of experiment, reaction times will be longer for the short than long delay. This effect of delay is usually attributed to preparation. The longer delay allows a subject to be more prepared, and as a result their responses are made more quickly than for short delay when they are less well prepared.
Raw Data. In the example, the tab character is the item-delimiter, or the character that separates items. Any character could potentially serve to distinguish items. Common item-delimiters are spaces, commas, and tabs.
The raw data for this experiment happens to be stored in a single file. The file is coded in long-format. The first column codes the subject number, the second column codes the trial number (from 1 to 100), the third column codes the delay (100 or 500 ms), and the fourth column codes the reaction time. As well, each of the values on each line are separated by a tab character.
The data file used in this example can be generated with the following R code. It will result in the creation of a file called DetectionData.txt. This file will be created in R’s current working directory.
Subjects<-c(rep(seq(1:20),each=200))
Trial<-c(rep(seq(1:200),20))
DelayA<-rep(c("100","500"),each=100)
Delay<-c()
for(i in 1:20){
Delay<-c(Delay,sample(DelayA))
}
RTs<-c()
for(i in 1:4000){
if(Delay[i]=="100"){
RTs<-c(RTs,rnorm(1,350,50))
} else {
RTs<-c(RTs,rnorm(1,250,50))
}
}
AllData<-data.frame(Subjects,Trial,Delay,RTs)
write.table(AllData, "DetectionData.txt", sep="\t")Here is a snippet of the data-file.
Attention to Detail. There are a few small formatting details to pay attention to. Notice that the first line only has four columns, and these are the column headers. The remaining lines have 5 columns. The column headers correspond only to columns 2-5. The first columns showing the numbers 1 to 19 is an artifact of exporting the data from R, it is listing the line number of the file. Each of the elements on each line is separated by a tab, so the whole .txt file can be opened up in excel, or copy and pasted into excel.
Quotes. Notice that some of the values have quotes around them. This is because these elements were defined as strings in R (we’ll learn about that later). How would you remove the quotes in this file without deleting them by hand? HINT: Use the find and replace tool in your text editor. Search for the quote symbol, and then have it be replaced by empty.
"Subjects" "Trial" "Delay" "RTs"
"1" 1 1 "500" 203.717273996492
"2" 1 2 "500" 181.979406770222
"3" 1 3 "100" 367.477194783578
"4" 1 4 "500" 180.092387295604
"5" 1 5 "100" 464.85308356188
"6" 1 6 "500" 273.797084225413
"7" 1 7 "100" 377.050544972311
"8" 1 8 "100" 368.745100165061
"9" 1 9 "500" 248.854487219306
"10" 1 10 "500" 246.525796202374
"11" 1 11 "500" 264.587480508185
"12" 1 12 "500" 187.00546363546
"13" 1 13 "500" 259.536440367878
"14" 1 14 "500" 251.831957663314
"15" 1 15 "500" 260.152767712989
"16" 1 16 "500" 224.443566487175
"17" 1 17 "500" 199.506051376675
"18" 1 18 "500" 186.622563446674
"19" 1 19 "500" 239.922482835083
...The next step is to open the file in Excel. Here is a screenshot. Notice that the headers are slightly out of alignment. The Subjects, Trials, Delay, and RTs need to be moved over by one. This is accomplished by hand in the screenshot below.
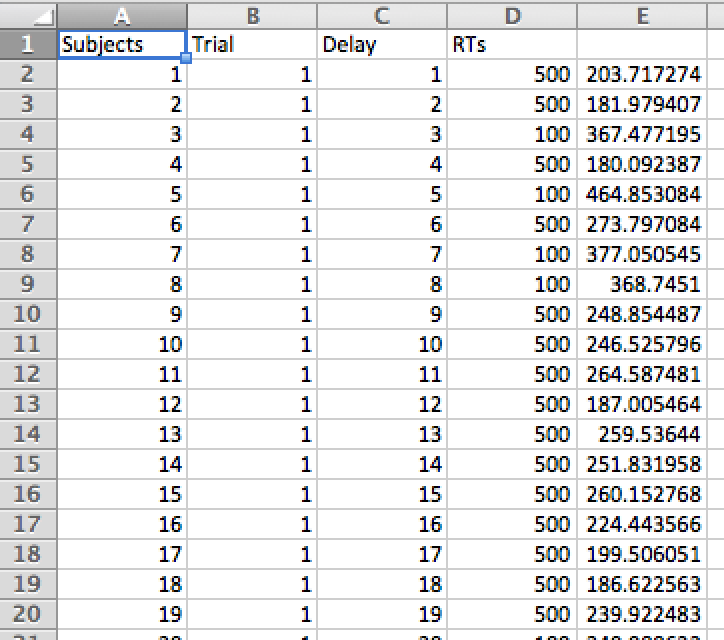
Figure 4.11: Example data
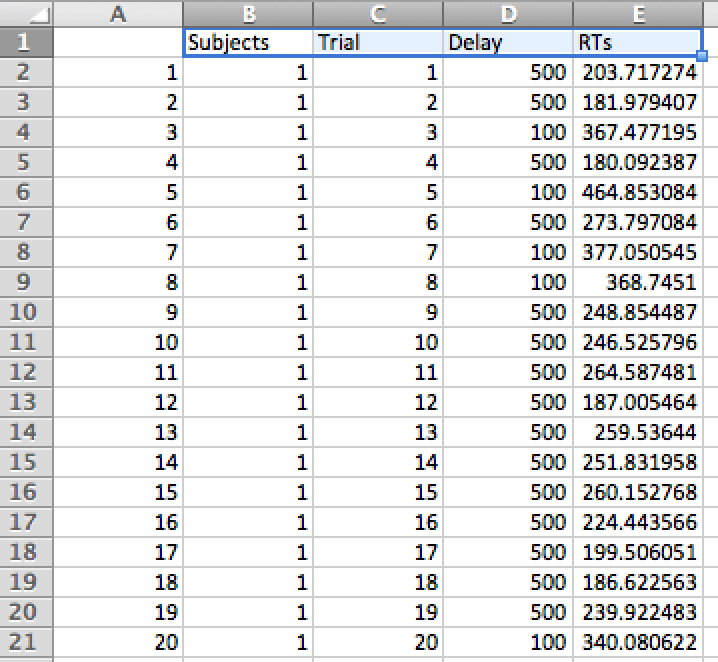
Figure 4.12: Changing the headers
Scrolling through the excel file will show that it is very long, it should have 4001 lines. 4000 lines of data and one line at the top for the headers. Each subject has 200 lines, coding their reaction time for each of the delay conditions. Notice also that the values in the Delay column (100 or 500) vary randomly from trial. This poses a problem for finding the means for each subject in each of the delay conditions.
The problem of finding the means for each subject in each delay condition is a problem of binning the data. For each subject we want to collect all of the individual reaction times from one delay condition, place them somewhere, then add them all up, and divide by the number of items in the bin. Then, this process is repeated for the second condition. And the whole process is repeated again for all of the subjects. If you are thinking about doing this by hand, you should stop now. Excel has an excellent tool suited for just this purpose.
4.3.1.0.1 Pivot Tables
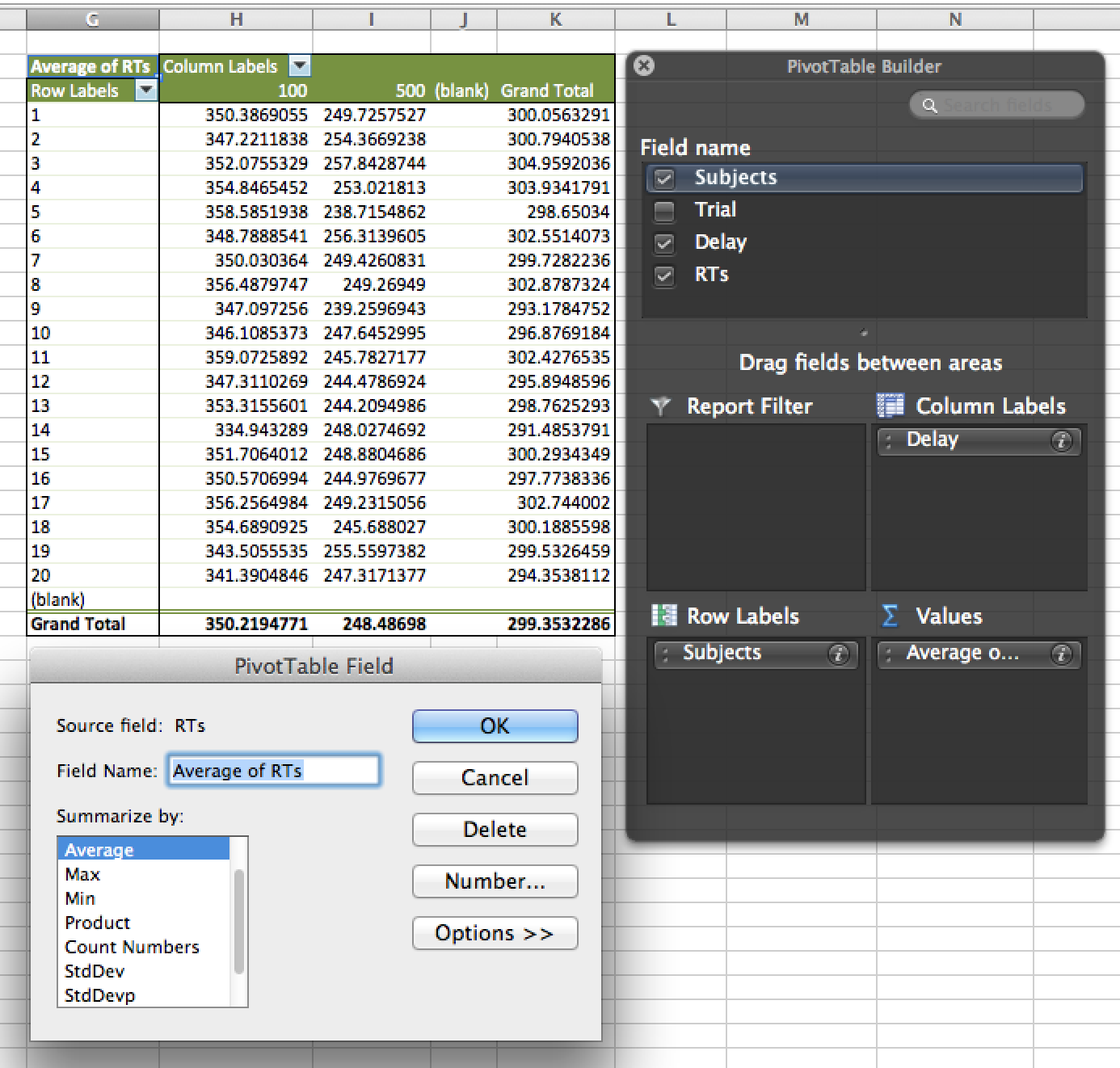
Figure 4.13: Pivot tables
Pivot tables can be used to produce summary statistics of data that is arranged in long-format. Luckily, our data is already formatted in long-format. One issue with pivot-tables in Excel is that their implementation changes slightly depending on the version of excel that you have. For this reason, and because self-study is important, this tutorial will not go through the nitty-gritty of using a pivot-table on your data. If you can’t figure it out, google it. There are plenty of tutorials out there. Nevertheless, here are the basic steps.
Select all of the data, including the headers. Then, in the excel menu choose Data, and select pivot table report. You will have options to place various aspects of your data into the pivot table. In this example, we place the subjects in the rows, the Delay condition in the columns, and ask for the average of the RTs column for the values of the Pivot Table. The resulting pivot table is shown below.
Notice that the pivot-table function has allowed use to not only find the means of each subject in each condition, but it has also transformed the data from long to wide format. The pivot table also provides summary statistics. The grand total column shows the average reaction time across conditions for each subject. And the grand total row at the bottom of the pivot table shows the average reaction across subjects for each condition.
The prediction for this experiment was that reaction times would be slower in the short than long delay conditions. Looking at the averages across subjects in the pivot table, we see that this pattern did emerge in the data. The next step would be to determine if this difference is statistically significant. You could check this yourself using the TTEST function in Excel.