
Chapter 6 Lab 6: t-Test (one-sample, paired sample)
Any experiment may be regarded as forming an individual of a ‘population’ of experiments which might be performed under the same conditions. A series of experiments is a sample drawn from this population. —William Sealy Gossett
This lab is modified and extended from Open Stats Labs. Thanks to Open Stats Labs (Dr. Kevin P. McIntyre) for their fantastic work.
6.2 Lab skills learned
- Conducting a one-sample t-test
- Conducting a two-sample t-test
- Plotting the data
- Discussing inferences and limitations
6.3 Important Stuff
- citation: Mehr, S. A., Song. L. A., & Spelke, E. S. (2016). For 5-month-old infants, melodies are social. Psychological Science, 27, 486-501.
- Link to .pdf of article
- Data in .csv format
- Data in SPSS format
6.4 R
6.4.1 Loading the data
The first thing to do is download the .csv formatted data file, using the link above, or just click here. It turns out there are lots of ways to load .csv files into R.
- Load the data.table library. Then use the
freadfunction and supply the web address to the file. Just like this. No downloading required.
library(data.table)
all_data <- fread("https://raw.githubusercontent.com/CrumpLab/statisticsLab/master/data/MehrSongSpelke2016.csv")- Or, if you downloaded the .csv file. Then you can use
fread, but you need to point it to the correct file location. The file location in this next example will not work for you, because the file is on my computer.
library(data.table)
all_data <- fread("data/MehrSongSpelke2016.csv")6.4.2 Inspect the data frame
When you have loaded data it’s always a good idea to check out what it looks like. You can look at all of the data in the environment tab on the top right hand corner. The data should be in a variable called all_data. Clicking on all_data will load it into a viewer, and you can scroll around. This can be helpful to see things. But, there is so much data, can be hard to know what you are looking for.
6.4.2.1 summarytools
The summarytools packages give a quick way to summarize all of the data in a data frame. Here’s how. When you run this code you will see the summary in the viewer on the bottom right hand side. There’s a little browser button (arrow on top of little window) that you can click to expand and see the whole thing in a browser.
library(summarytools)
view(dfSummary(all_data))6.4.3 Get the data for Experiment one
The data contains all of the measurements from all five experiments in the paper. By searching through the all_data data frame, you should look for the variables that code for each experiment. For example, the third column is called exp1, which stands for experiment 1. Notice that it contains a series of 1s. If you keep scrolling down, the 1s stop. These 1s identify the rows associated with the data for Experiment 1. We only want to analyse that data. So, we need to filter our data, and put only those rows into a new variable. We do this with the dplyr library, using the filter function.
library(dplyr)
experiment_one <- all_data %>% filter(exp1==1)Now if you look at the new variable experiment_one, there are only 32 rows of data. Much less than before. Now we have the data from experiment 1.
6.4.4 Baseline phase: Conduct a one sample t-test
You first want to show that infants’ looking behavior did not differ from chance during the baseline trial. The baseline trial was 16 seconds long. During the baseline, infants watched a video of two unfamiliar people, one of the left and one on the right. There was no sound during the baseline. Both of the actors in the video smiled directly at the infant.
The important question was to determine whether the infant looked more or less to either person. If they showed no preference, the infant should look at both people about 50% of the time. How could we determine whether the infant looked at both people about 50% of the time?
The experiment_one data frame has a column called Baseline_Proportion_Gaze_to_Singer. All of these values show how the proportion of time that the infant looked to the person who would later sing the familiar song to them. If the average of these proportion is .5 across the infants, then we would have some evidence that the infants were not biased at the beginning of the experiment. However, if the infants on average had a bias toward the singer, then the average proportion of the looking time should be different than .5.
Using a one-sample t-test, we can test the hypothesis that our sample mean for the Baseline_Proportion_Gaze_to_Singer was not different from .5.
To do this in R, we just need to isolate the column of data called Baseline_Proportion_Gaze_to_Singer. We will do this using the $ operator. The $ operator is placed after any data frame variable, and allows you to select a column of the data. The next bit of code will select the column of data we want, and put it into a new variable called Baseline. Note, if you type exp1$ then R-Studio should automatically bring up all the columns you can choose from.
baseline <- experiment_one$Baseline_Proportion_Gaze_to_Singer6.4.4.1 Look at the numbers
Question: Why is it important to look at your numbers? What could happen if you didn’t?
OK, we could just do the t-test right away, it’s really easy, only one line of code. But, we haven’t even looked at the numbers yet. Let’s at least do that. First, we’ll just use plot. It will show every data point for each infant as a dot.
plot(baseline)
That’s helpful, we see that the dots are all over the place. Let’s do a histogram, so we can get a better sense of the frequency of different proportions.
hist(baseline)
6.4.4.2 Look at the descriptives
Let’s get the mean and standard deviation of the sample
mean(baseline)## [1] 0.5210967sd(baseline)## [1] 0.1769651OK, so just looking at the mean, we see the proportion is close to .5 (it’s .521). And, we see there is a healthy amount of variance (the dots were all over the place), as the standard deviation was about .176.
Question: Based on the means and standard deviations can you make an educated guess about what the t and p values might be? Learn how to do this and you will be improving your data-sense.
Now, before we run the t-test, what do you think is going to happen? We are going to get a t-value, and an associated p-value. If you can make a guess at what those numbers would be right now in your head, and those end up being pretty close to the ones we will see in a moment, then you should pat yourself on the back. You have learned how to have intuitions about the data. As I am writing this I will tell you that 1) I can’t remember what the t and p was from the paper, and I haven’t done the test yet, so I don’t know the answer. So, I am allowed to guess what the answer will be. Here are my guesses t(31) = 0.2, p = .95. The numbers in the brackets are degrees of freedom, which we know are 31 (df= n-1 = 32-1= 31). More important than the specific numbers I am guessing (which will probably be wrong), I am guessing that the p-value will be pretty large, it will not be less than .05, which the author’s set as their alpha rate. So, I am guessing we will not reject the hypothesis that .52 is different from .5.
Let’s do the t-test and see what happens.
6.4.4.3 Conduct t.test
t.test(baseline, mu=.5)##
## One Sample t-test
##
## data: baseline
## t = 0.67438, df = 31, p-value = 0.5051
## alternative hypothesis: true mean is not equal to 0.5
## 95 percent confidence interval:
## 0.4572940 0.5848994
## sample estimates:
## mean of x
## 0.5210967Question: Why was the baseline condition important for the experiment? What does performance in this condition tell us?
So, there we have it. We did a one-sample t-test. Here’s how you would report it, t(31) = .67, p = .505. Or, we might say something like:
During the baseline condition, the mean proportion looking time toward the singer was .52, and was not significantly different from .5, according to a one-sample test, t(31) = .67, p = .505.
You should take the time to check this result, and see if it is the same one that was reported in the paper.
6.4.5 Test phase
Remember how the experiment went. Infants watched silent video recordings of two women (Baseline). Then each person sung a song, one was familiar to the infant (their parents sung the song to them many times), and one was unfamiliar (singing phase). After the singing phase, the infants watched the silent video of the two singers again (test phase). The critical question was whether the infants would look more to the person who sung the familiar song compared to the person who sun the unfamiliar song. If the infants did this, they should look more than 50% of the time to the singer who sang the familiar song. We have the data, we can do another one sample t-test to find out. We can re-use all the code we already wrote to do this. I’ll put it all in one place. If we run all of this code, we will see all of the things we want to see.
We only need to make two changes. We will change experiment_one$Baseline_Proportion_Gaze_to_Singer to experiment_one$Test_Proportion_Gaze_to_Singer, because that column has the test phase data. And, instead of putting the data into the variable baseline. We will make a new variable called test_phase to store the data.
test_phase <- experiment_one$Test_Proportion_Gaze_to_Singer
plot(test_phase)
hist(test_phase)
mean(test_phase)## [1] 0.5934913sd(test_phase)## [1] 0.1786884t.test(test_phase, mu = .5)##
## One Sample t-test
##
## data: test_phase
## t = 2.9597, df = 31, p-value = 0.005856
## alternative hypothesis: true mean is not equal to 0.5
## 95 percent confidence interval:
## 0.5290672 0.6579153
## sample estimates:
## mean of x
## 0.5934913Question: Why was the test condition important for the experiment? What does performance in this condition tell us?
Alright. What did we find? You should take a stab at writing down what we found. You can use the same kind of language that I used from the first one sample-test. You should state the mean proportion, the t-value, the dfs, and the p-value. You should be able to answer the question, did the infants look longer at the singer who sang the familiar song? And, did they look longer than would be consist with chance at 50%.
6.4.6 Paired-samples t-test
The paired samples t-test is easy to do. We’ve already made two variables called baseline, and test_phase. These contain each of the infants looking time proportions to the singer for both parts of the experiment. We can see if the difference between them was likely or unlikely due to chance by running a paired samples t-test. We do it like this in one line:
t.test(test_phase, baseline, paired=TRUE, var.equal=TRUE)##
## Paired t-test
##
## data: test_phase and baseline
## t = 2.4164, df = 31, p-value = 0.02175
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.01129217 0.13349698
## sample estimates:
## mean of the differences
## 0.07239458Question: Why was the paired samples t-test necessary if we already did two one sample t-test? What new question is the paired samples t-test asking?
I’ll leave it to you to interpret these values, and to see if they are the same as the ones in the paper. Based on these values what do you conclude? Is there a difference between the mean proportion looking times for the baseline and testing phase?
6.4.6.1 Relationship between one-sample and paired sample t-test
Question: Why is it that a paired samples t-test can be the same as the one sample t-test? What do you have to do the data in the paired samples t-test in order to conduct a one-sample t-test that would give you the same result?
We’ve discussed in the textbook that the one-sample and paired sample t-test are related, they can be the same test. The one-sample test whether a sample mean is different from some particular mean. The paired sample t-test, is to determine whether one sample mean is different from another sample mean. If you take the scores for each variable in a paired samples t-test, and subtract them from one another, then you have one list of difference scores. Then, you could use a one sample t-test to test whether these difference scores are different from 0. It turns out you get the same answer from a paired sample t-test testing the difference between two sample means, and the one sample t-test testing whether the mean difference of the difference scores between the samples are different from 0. We can show this in r easily like this:
t.test(test_phase, baseline, paired=TRUE, var.equal=TRUE)##
## Paired t-test
##
## data: test_phase and baseline
## t = 2.4164, df = 31, p-value = 0.02175
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.01129217 0.13349698
## sample estimates:
## mean of the differences
## 0.07239458difference_scores<-test_phase-baseline
t.test(difference_scores, mu=0)##
## One Sample t-test
##
## data: difference_scores
## t = 2.4164, df = 31, p-value = 0.02175
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 0.01129217 0.13349698
## sample estimates:
## mean of x
## 0.072394586.4.6.2 Usefulness of difference scores
OK fine, the paired samples t-test can be a one sample t-test if you use the difference scores. This might just seem like a mildly useful factoid you can use for stats trivia games (which no one plays). The point of drawing your attention to the relationship, is to get you to focus on the difference scores. These are what we are actually interested in.
Let’s use the difference scores to one more useful thing. Sometime the results of a t-test aren’t intuitively obvious. By the t-test we found out that a small difference between the test phase and baseline was not likely produced by chance. How does this relate to the research question about infants using familiar songs as cues for being social? Let’s ask a very simple question. How many infants actually showed the bias? How many infants out of 32 looked longer at the singer who sang the familiar song during test, compared to during baseline.
We can determine this by calculating the difference scores. Then, asking how many of them were greater than zero:
difference_scores <- test_phase-baseline
length(difference_scores[difference_scores>0])## [1] 22So, 22 out of 32 infants showed the effect. To put that in terms of probability, 68.75% of infants showed the effect. These odds and percentages give us another way to appreciate how strong the effect is. It wasn’t strong enough for all infants to show it.
6.4.7 Graphing the findings
It is often useful to graph the results of our analysis. We have already looked at dot plots and histograms of the individual samples. But, we also conducted some t-tests on the means of the baseline and test_phase samples. One of the major questions was whether these means are different. Now, we will make a graph that shows the means for each condition. Actually, we will make a few different graphs, so that you can think about what kinds of graphs are most helpful. There are two major important things to show: 1) the sample means, and 2) a visual aid for statistical inference showing whether the results were likely due to chance.
We will use the ggplot2 package to make our graphs. Remember, there are two steps to take when using ggplot2. 1) put your data in a long form data frame, where each measure has one row, and 2) define the layers of the ggplot.
6.4.7.1 Make the dataframe for plotting
To start we will need 2 columns. One column will code the experimental phase, Baseline or Test. There are 32 observations in each phase, so we want the word Baseline to appear 32 times, followed by the word Test 32 times. Then we want a single column with each of the proportions for each infant.
Phase <- rep(c("Baseline","Test"), each = 32)
Proportions <- c(baseline,test_phase)
plot_df <- data.frame(Phase,Proportions)6.4.7.2 Dot plot of raw scores
This shows every scores value on the y-axis, split by the baseline and test groups. If you just looked at this, you might not think the test phase was different from the baseline phase. Still very useful to see the spread of individual scores. Supports the intuition that the scores are still kind of in a similar ballpark.
library(ggplot2)
ggplot(plot_df, aes(x=Phase, y=Proportions))+
geom_point()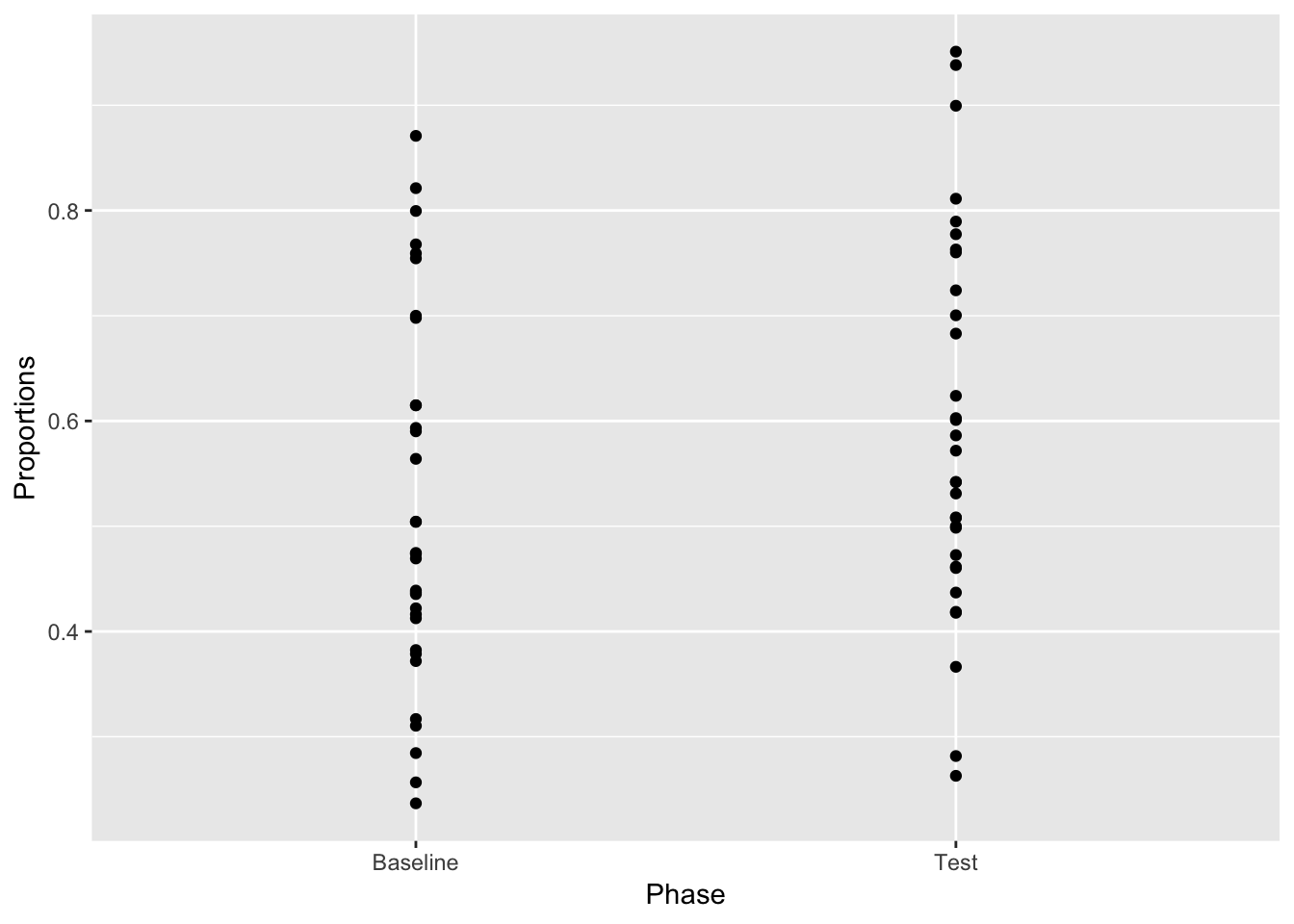
6.4.7.3 Dot plot with means and raw scores
Question: What kinds of inferences about the role of chance in producing the difference between the means can we make from this graph? What is missing?
ggplot2 is great because it let’s us add different layers on top of an existing plot. It would be good to see where the mean values for each sample lie on top of the sample scores. We can do this. But, to do it, we need to supply ggplot with another data frame, one that contains the means for each phase in long form. There are are only two phases, and two means, so we will make a rather small data.frame. It will have two columns, a Phase column, and Mean_value column. There will only be two rows in the data frame, one for the mean for each phase.
To make the smaller data frame for the means we will use the aggregate function. This allows us to find the means for each phase from the plot_df data frame. It also automatically returns the data frame we are looking for.
mean_df <- aggregate(Proportions ~ Phase, plot_df, mean)
ggplot(plot_df, aes(x=Phase, y=Proportions))+
geom_point()+
geom_point(data=mean_df, color="Red", size=2)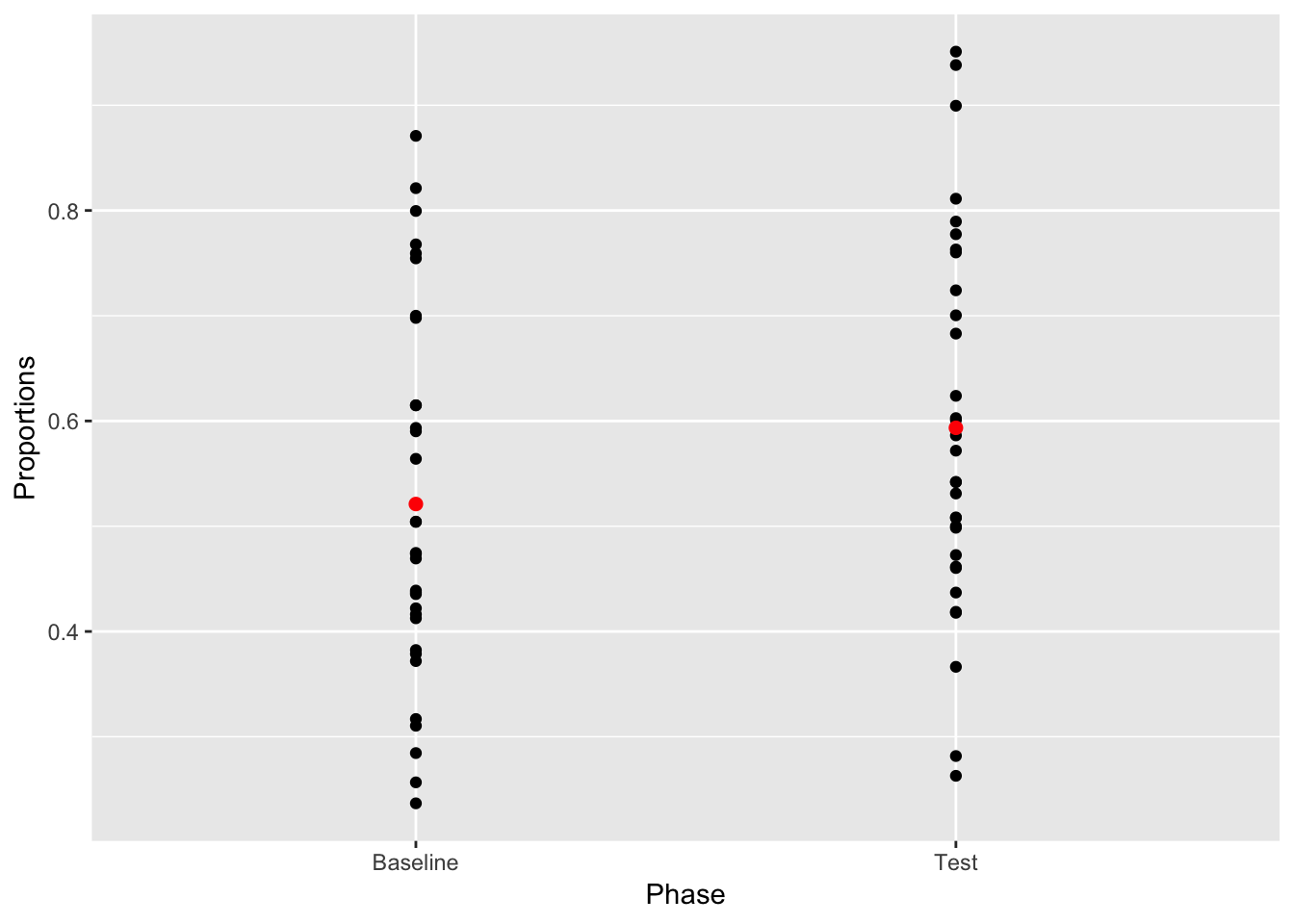
6.4.7.4 Bar plot
It’s very common to use bars in graphs. We can easily do this by using geom_bar, rather than geom_point. Also, we can plot bars for the means, and keep showing the dots like this…(note this will be messed up, but I want to show you why).
Also look for these changes.
- added
stat="identity"Necessary for bar plot to show specific numbers - added
aes(fill=Phase)Makes each bar a different color, depending on which phase it comes from
ggplot(plot_df, aes(x=Phase, y=Proportions))+
geom_point()+
geom_bar(data=mean_df, stat="identity",aes(fill=Phase))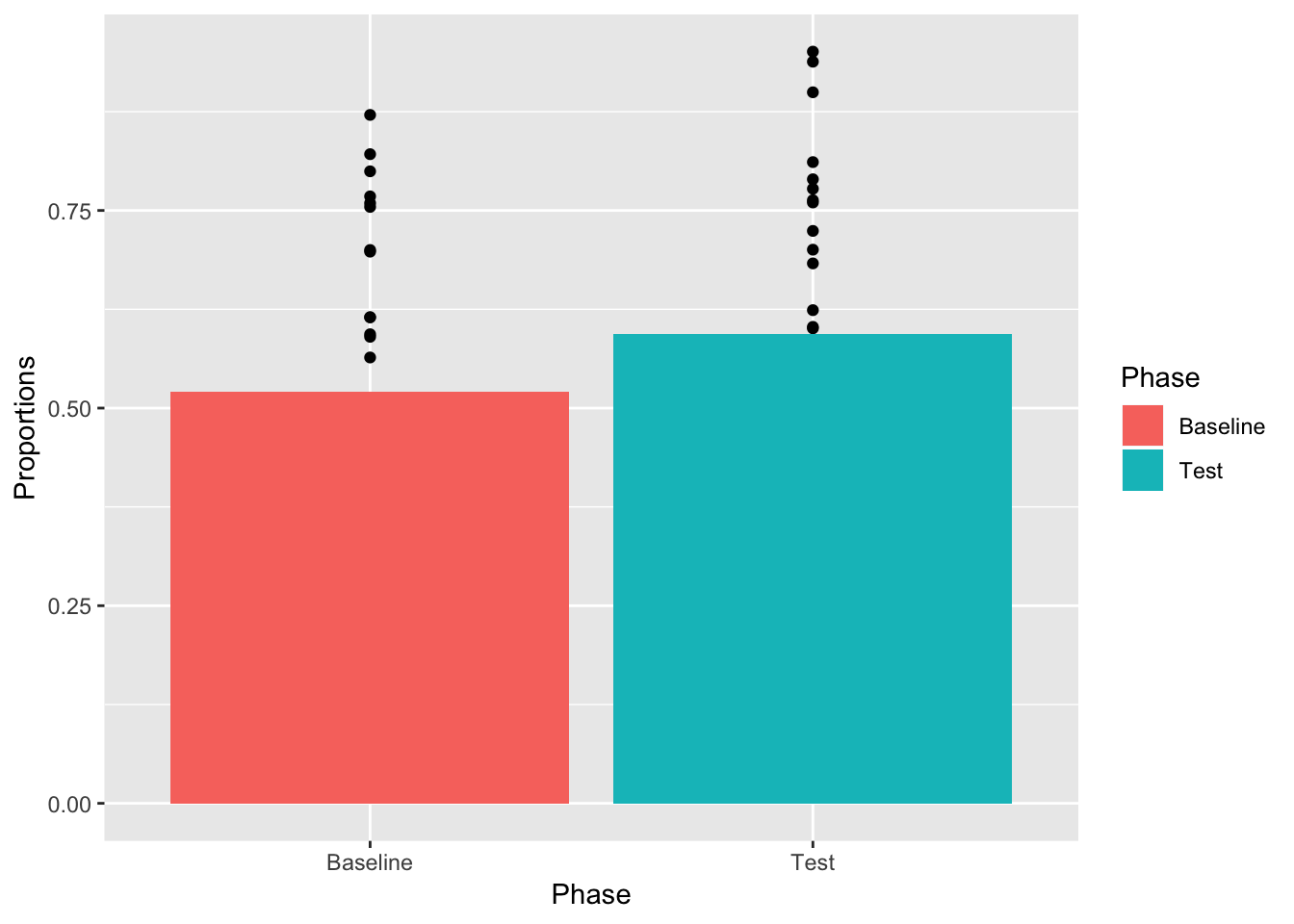
OK, we see the bars and some of the dots, but not all of them. What is going on? Remember, ggplot2 works in layers. Whatever layer you add first will be printed first in the graph, whatever layer you add second will be printed on top of the first. We put the bars on top of the dots. Let’s change the order of the layers so the dot’s go on top of the bars.
ggplot(plot_df, aes(x=Phase, y=Proportions))+
geom_bar(data=mean_df, stat="identity",aes(fill=Phase))+
geom_point()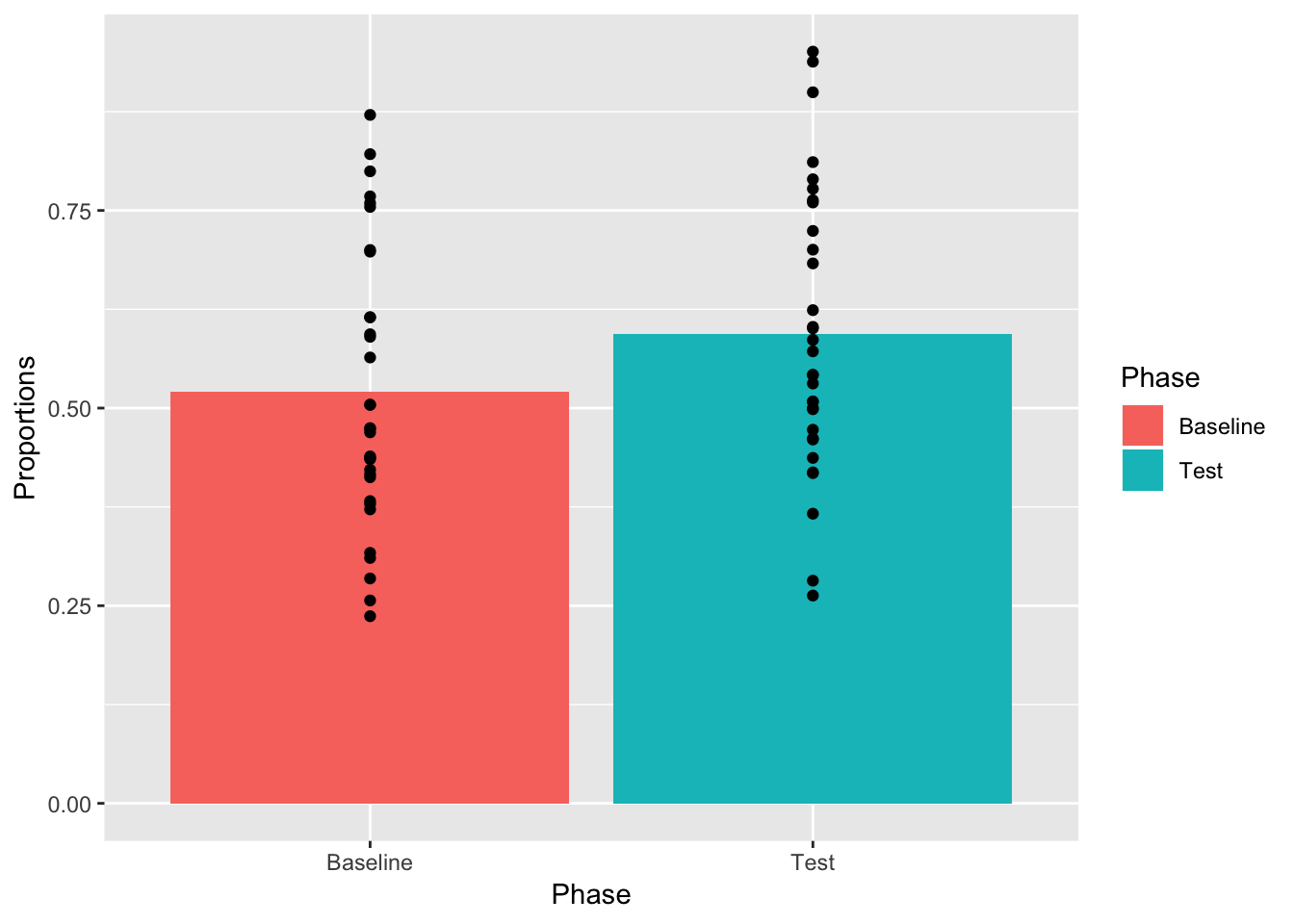
6.4.7.5 Bar plot with error bars
So far we have only plotted the means and individual sample scores. These are useful, but neither of them give us clear visual information about our statistical test. Our paired sample t-test suggested that the mean difference between Baseline and Test was not very likely by chance. It could have happened, but wouldn’t happen very often.
Question: Why would the standard deviation of each mean, or the standard error of each mean be inappropriate to use in this case?
Question: How would error bars based on the standard error of the mean differences aid in visual inference about the role of chance in producing the difference?
Error bars are commonly used as an aid for visual inference. The use of error bars can be a subtle nuanced issue. This is because there a different kinds of error bars that can be plotted, and each one supports different kinds of inference. In general, the error bar is supposed to represent some aspect of the variability associated with each mean. We could plot little bars that are +1 or -1 standard deviations of each mean, or we would do +1 or -1 standard errors of each mean. In the case of paired samples, neither or these error bars would be appropriate, they wouldn’t reflect the variability associated with mean we are interested in. In a paired samples t-test, we are interested in the variability of the mean of the difference scores. Let’s calculate the standard error of the mean (SEM) for the difference scores between Baseline and Test, and then add error bars to the plot.
difference_scores <- baseline-test_phase #calculate difference scores
standard_error <- sd(difference_scores)/sqrt(length(difference_scores)) #calculate SEM
ggplot(plot_df, aes(x=Phase, y=Proportions))+
geom_bar(data=mean_df, stat="identity",aes(fill=Phase))+
geom_errorbar(data=mean_df, aes(ymin=Proportions-standard_error,
ymax=Proportions+standard_error), width=.1) +
geom_point(alpha=.25)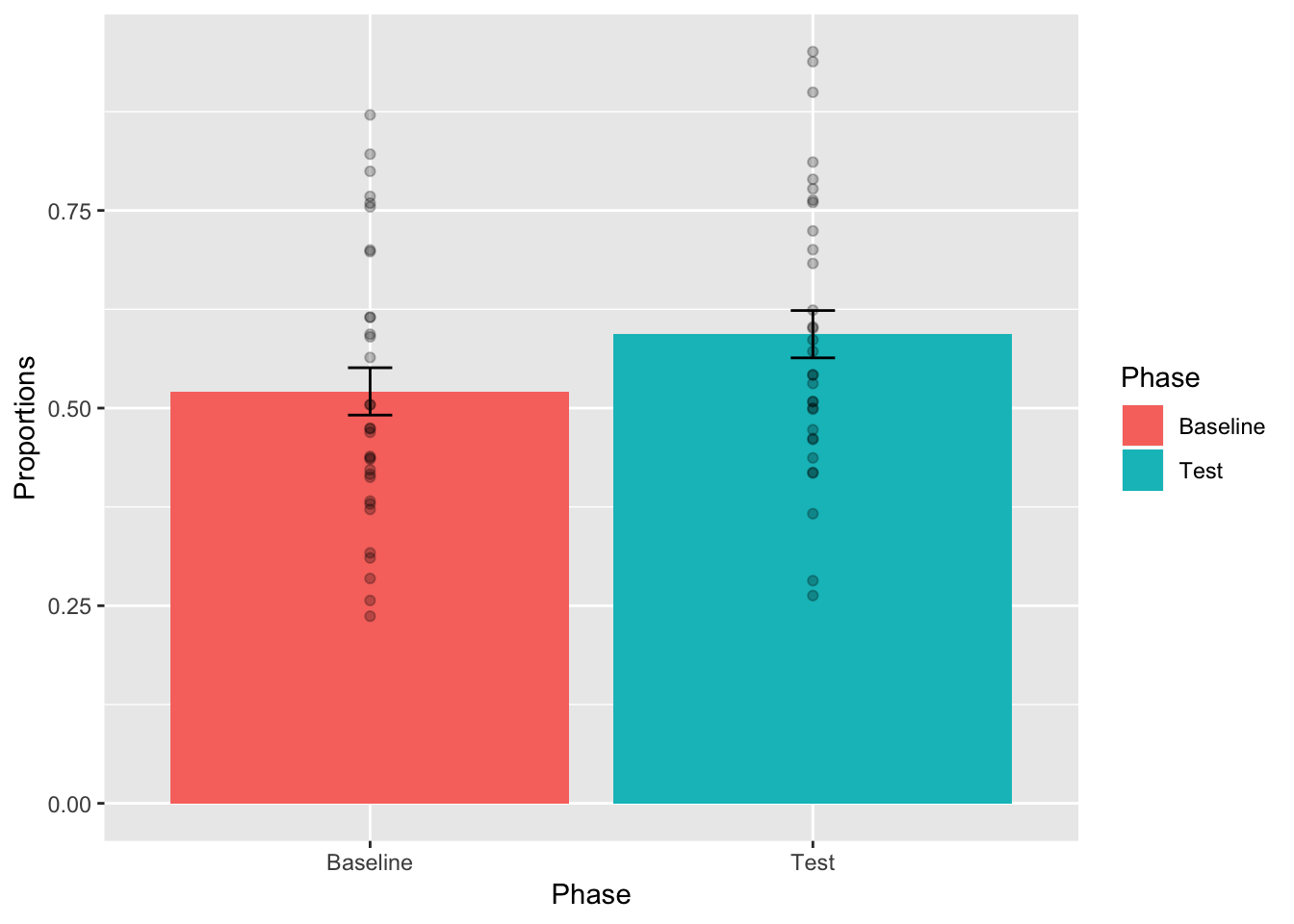
Question: What is one reason why these error bars (standard error of the mean difference between Baseline and Test) are appropriate to use. What is one reason they are not appropriate to use?
We have done something that is useful for visual inference. From the textbook, we learned that differences of about 2 standard errors of the mean are near the point where we would claim that chance is unlikely to have produced the difference. This is a rough estimate. But, we can see that the top of the error bar for Baseline is lower than the bottom of the error bar for Test, resulting in a difference greater than 2 standard error bars. So, based on this graph, we might expect the difference between conditions to be significant. We can also complain about what we have done here, we are placing the same error bars from the mean difference scores onto the means for each condition. In some sense this is misleading. The error bars are not for the depicted sample means, they are for the hidden single set of difference scores. To make this more clear, we will make a bar plot with a single bar only for the differences scores.
difference_scores <- test_phase-baseline #calculate difference scores
standard_error <- sd(difference_scores)/sqrt(length(difference_scores)) #calculate SEM
mean_difference <- mean(difference_scores)
qplot(x="MeanDifference", y=mean_difference)+
geom_bar(stat="identity", width=.5, alpha=.5)+
geom_hline(yintercept=0)+
geom_point(aes(y=difference_scores), alpha=.25)+
geom_errorbar(aes(ymin=mean_difference-standard_error,
ymax=mean_difference+standard_error), width=.1)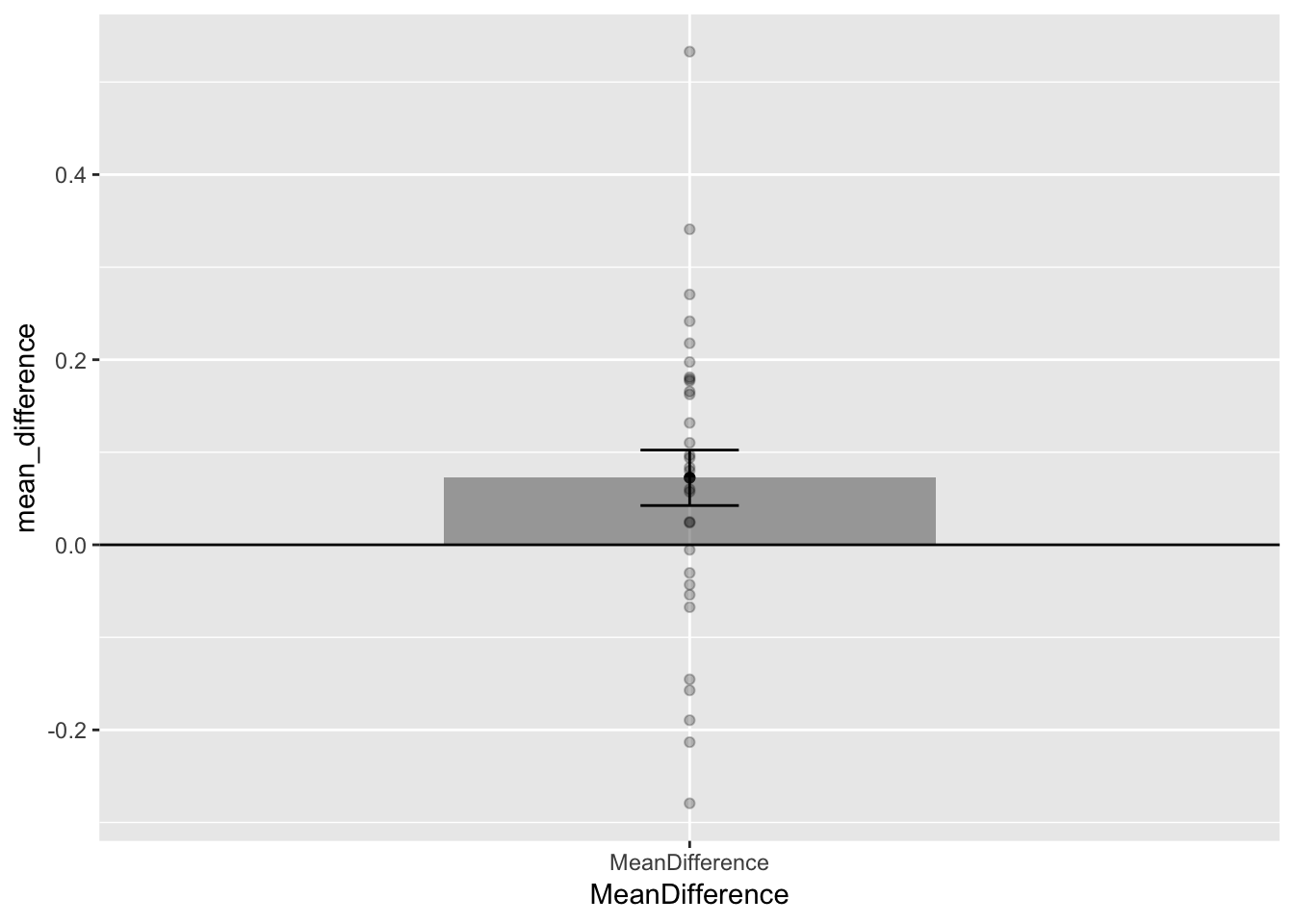
Question: Why is is it more appropriate to put the standard error of the difference on this bar graph? What important aspects of the original results shown in the previous graph are missing from this graph?
This plot is very useful too, it gives us some new information. We can see that the mean difference (test - baseline) was greater than 0. And, we are plotting the standard error of the mean differences, which are the error bars that more formally belong to this graph. Still, we are in a position to make some guesses for visual inference. The lower error bar represents only 1 SEM. It does not cross 0, but the fact that 1 SEM does not cross zero isn’t important. For SEMs it’s usually closer to 2. We can sort of visually guesstimate that that 2 SEMs would not cross zero, which would suggest we would obtain a small p-value. We also see each of the mean difference scores. It’s very clear that they are all over the place. This means that not every infant showed a looking time preference toward the singer of the familiar song. Finally, this single bar plot misses something. It doesn’t tell us what the values of the original means were.
6.4.7.6 Bar plot with confidence intervals
Confidence intervals are also often used for error bars, rather than the standard error (or other measure of variance). If we use 95% confidence intervals, then our error bars can be even more helpful for visual inference. Running the t.test function produces confidence interval estimates, and we can pull them out and use them for error bars.
t_test_results <- t.test(difference_scores)
lower_interval<- t_test_results$conf.int[1]
upper_interval<- t_test_results$conf.int[2]
qplot(x="MeanDifference", y=mean_difference)+
geom_bar(stat="identity", width=.5, alpha=.5)+
geom_hline(yintercept=0)+
geom_point(aes(y=difference_scores), alpha=.25)+
geom_errorbar(aes(ymin=lower_interval,
ymax=upper_interval), width=.1)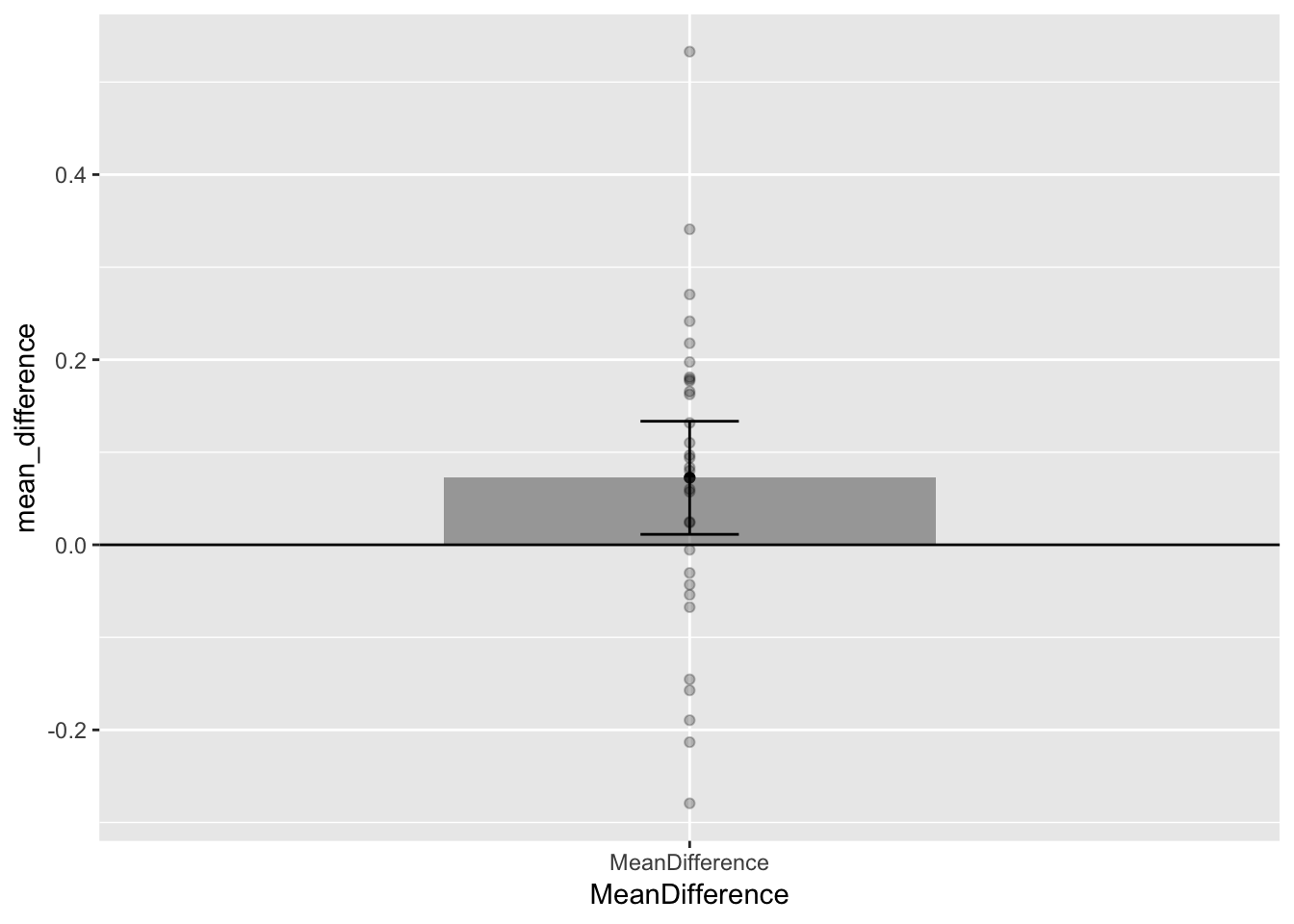
Notice that the 95% confidence intervals around the mean are wider than the SEM error bars from the previous graph. These new confidence intervals tell us that 95% of the time our sample mean will fall between the two lines. The bottom line is slightly above 0, so we can now visually see support for our statistical inference that chance was unlikely to produce the result. If chance was likely to produce the result, the horizontal line indicating 0, would be well inside the confidence interval. We can also notice that the mean difference was just barely different from chance, that lower bar is almost touching 0.
6.4.8 Data-simulation
We can do a little bit of data simulation to get a better feel for this kind of data. For example, we saw that the dots in our plots were quite variable. We might wonder about what chance can do in the current experiment. One way to do this is to estimate the standard deviation of the looking time proportions. Perhaps the best way to do that would be to an average of the standard deviation in the baseline and test_phase conditions. Then, we could simulate 32 scores from a normal distribution with mean = .5, and standard deviation equaling our mean standard deviation. We could calculate the mean of our simulated sample. And, we could do this many times, say 1000 times. Then, we could look at a histogram of our means. This will show the range of sample means we would expect just by chance. This is another way to tell whether the observed difference in this experiment in the testing phase was close or not close from being produced by chance. Take a look at the histogram. What do you think?
sample_sd <- (sd(baseline)+sd(test_phase))/2
simulated_means <- length(1000)
for(i in 1:1000){
simulated_means[i] <- mean(rnorm(32,.5, sample_sd))
}
hist(simulated_means)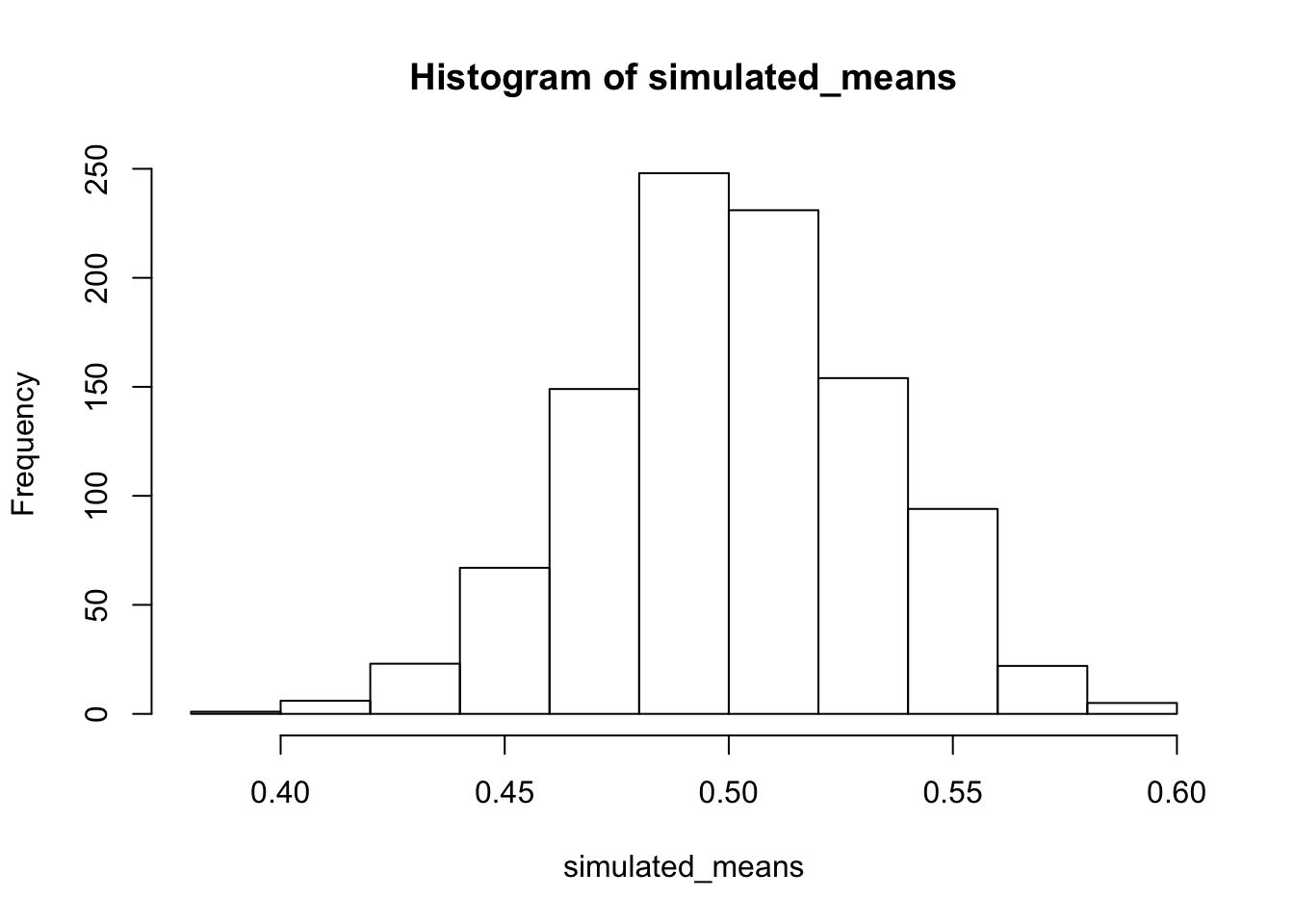 #### Simulating the mean differences
#### Simulating the mean differences
We can do the simulation slightly differently to give us a different look at chance. Above we simulated the sample means from a normal distribution centered on .5. The experimental question of interest was whether the mean difference between the baseline and test_phase condition was different. So, we should do a simulation of the difference scores. First, we estimate the standard deviation of the difference scores, and then run the simulation with a normal distribution centered on 0 (an expected mean difference of 0). This shows roughly how often we might expect mean differences of various sizes to occur. One major limitation is that we likely had only a rough estimate of the true standard deviation of these mean differences, after all there were only 32 of them, so we should take this with a grain of salt. Nevertheless, the pattern in the simulation fits well with the observations in that we already made from the data.
sample_sd <- sd(baseline-test_phase)
simulated_mean_difference <- length(1000)
for(i in 1:1000){
simulated_mean_difference[i] <- mean(rnorm(32,0, sample_sd))
}
hist(simulated_mean_difference)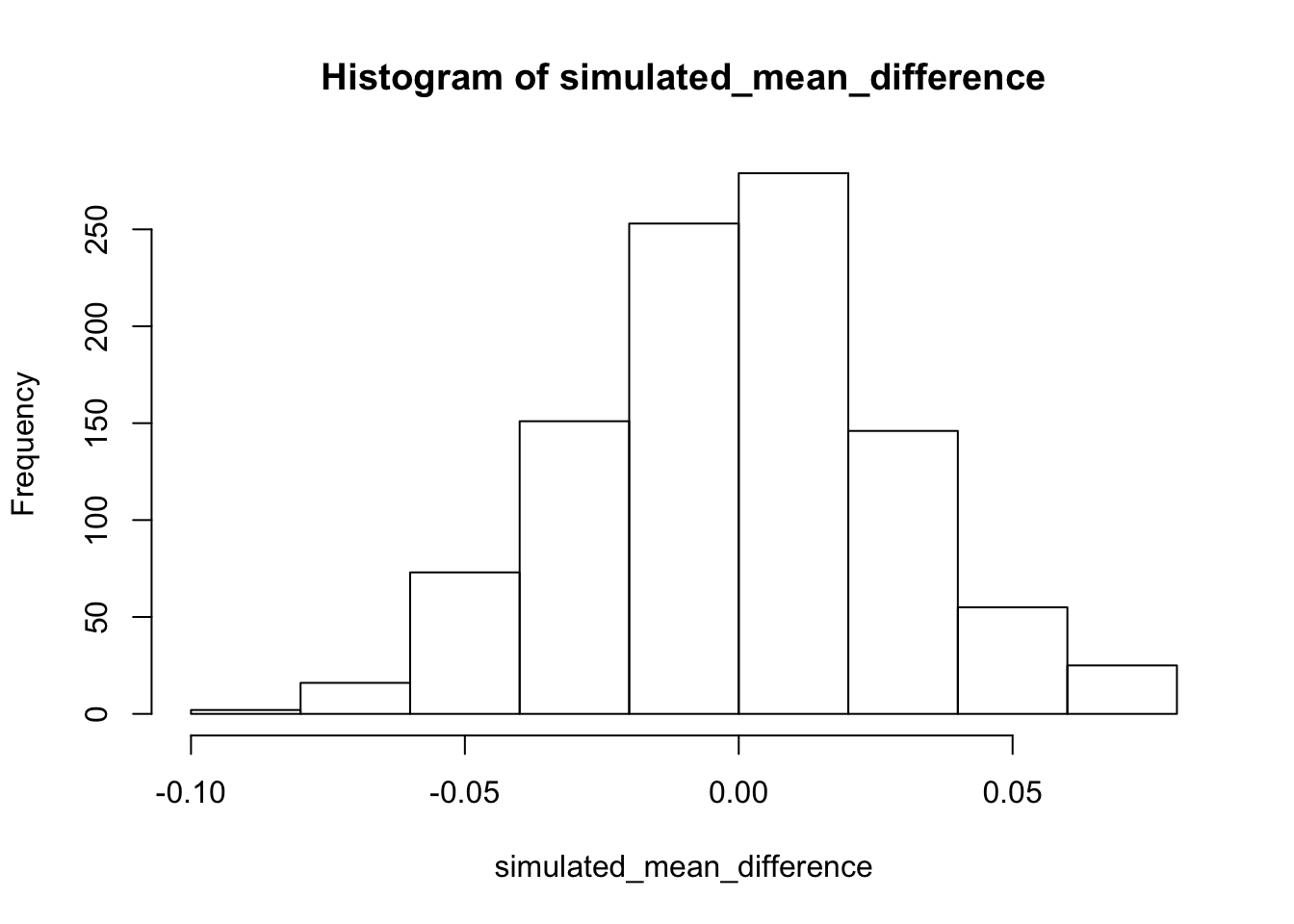
6.4.9 Generalization Exercise
( 1 point - Pass/Fail )
The following code creates two variables with simulated means for each of 20 subjects in two conditions (A and B). Each sample comes from a normal distribution with mean = 100, and standard deviation = 25.
Condition_A <- rnorm(20,100,25)
Condition_B <- rnorm(20,100,25)Conduct a paired samples t-test on sample data stored in the variables
Condition_A, andCondition_B. Report the results of the t-test, and the mean difference between conditionsThe above code assumes no difference in the means between Condition A and Condition B. Both samples come from the same normal distribution. Change the mean for one of the distributions. Make the change large enough so that you find a significant p-value (p < 0.05) when you conduct the t-test on the new simulated data. Report the t-test and the means for each condition
6.4.10 Writing assignment
(2 points - Graded)
Complete the writing assignment described in your R Markdown document for this lab. When you have finished everything. Knit the document and hand in your stuff (you can submit your .RMD file to blackboard if it does not knit.)
- Answer the following questions
Explain the general concept of a t value, and how it is different from a mean and the standard error. (.33 points)
Imagine you obtained a t-value with an associated p-value of .25. Explain what this means. (.33 points)
Imagine the critical t value for a particular test was 2.6. What does the critical t-value mean (assuming alpha = 0.05 and the test is two-tailed) (.33 points)
Explain the differences between a one-sample and paired-sample t-test ( 1 point )
General grading.
- You will receive 0 points for missing answers
- You must write in complete sentences. Point form sentences will be given 0 points.
- Completely incorrect answers will receive 0 points.
- If your answer is generally correct but very difficult to understand and unclear you may receive half points for the question
6.5 Excel
How to do it in Excel
6.6 SPSS
In this lab, we will use SPSS to:
- Perform a one-sample t-test
- Perform a paired-samples t-test
- Graph the data
- Assess the relationship between a one-sample and a paired-samples t-test
6.6.1 Experiment Background
For this lab, we will be using the data from Mehr, Song, and Spelke’s (2016) study of how music may convey important social information to infants.
To test their hypothesis, the researchers recruited 32 infants and their parents to complete an experiment. During their first visit to the lab, the parents were taught a new lullaby (one that neither they nor their infants had heard before).The experimenters asked the parents to sing the new lullaby to their child every day for the next 1-2 weeks.
Following this exposure period, the parents and their infant returned to the lab to complete the experimental portion of the study. Infants were first shown a screen with side-by-side videos of two unfamiliar people, each of whom were silently smiling and looking at the infant. The researchers recorded the looking behavior (or gaze) of the infants during this ‘baseline’ phase. Next, one by one, the two unfamiliar people on the screen sang either the lullaby that the parents learned or a different lullaby (that had the same lyrics and rhythm, but a different melody). Finally, the infants saw the same silent video used at baseline, and the researchers again recorded the looking behavior of the infants during this ‘test’ phase.
6.6.2 Performing a one-sample t-test
First, let’s open the relevant data file; Here is the link. It’s called “MehrSongSpelke2016_Experiment1.sav” Open this file in SPSS. Your data should look like this:
We will use SPSS to determine whether the infants looked equally at each of the people in the side-by-side videos at baseline. Let’s think about why this is important. The infants in this experiment watched silent video recordings of two women (Baseline). Later, each person sungs a song, one familiar (their parents sung the song to them many times), and one unfamiliar. Afterwards, the infants watched the silent video of the two singers again (test phase). The critical question was whether the infants would look more to the person who sung the familiar song compared to the person who sung the unfamiliar song.
If the measure of what infants “like” or “prefer” is based on how long they look at a stimulus (in this case, a person in a video), we need to know that at baseline (before either of the people were associated with a song), infants looked equally at each person. If one of the people in the video was more memorable or attractive to the infants, then they would have a preferential bias towards looking at one person over the other. This could mean that the results of the study may have nothing to do with the songs, but rather an inherent bias towards the appearance of one of the people. This is why it is important to ensure that the infants looked at the people equally to start with (at baseline).
In our data file, the variable we will use is called “Baseline_Proportion_Gaze_to_Singer”; this variable represents the proportion of time (out of 100%) that the infant spent looking at the person who would later be the singer of the familiar song. If the infant looks equally at each person, then the proportion of time spent looking at one out of the two people should be .5, or half of the time. Thus, we want to test whether the proportions measured are different from .5. Whenever we want to compare a sample data set (the proportions measured for all 32 infants) to a known mean (.5, or the proportion we expect if infants looked equally at both people), we use a one-sample t-test.
Before we begin, it’s important to notice that our data file has 96 rows in it, for 96 infants. However, Experiment 1 only used 32 infants. If you find the column labeled exp1, it will show you which infants belong to that experiment. You’ll notice there are a series of 1s (32 of them, to be exact) signifying the infants in Experiment 1. We will have to split our data file so we can run subsequent analyses only on this Experiment 1 data.
Go to Data, then Split file…
A window will appear. Choose Organize output by groups and enter the exp1 variable in the “Groups Based on” field:
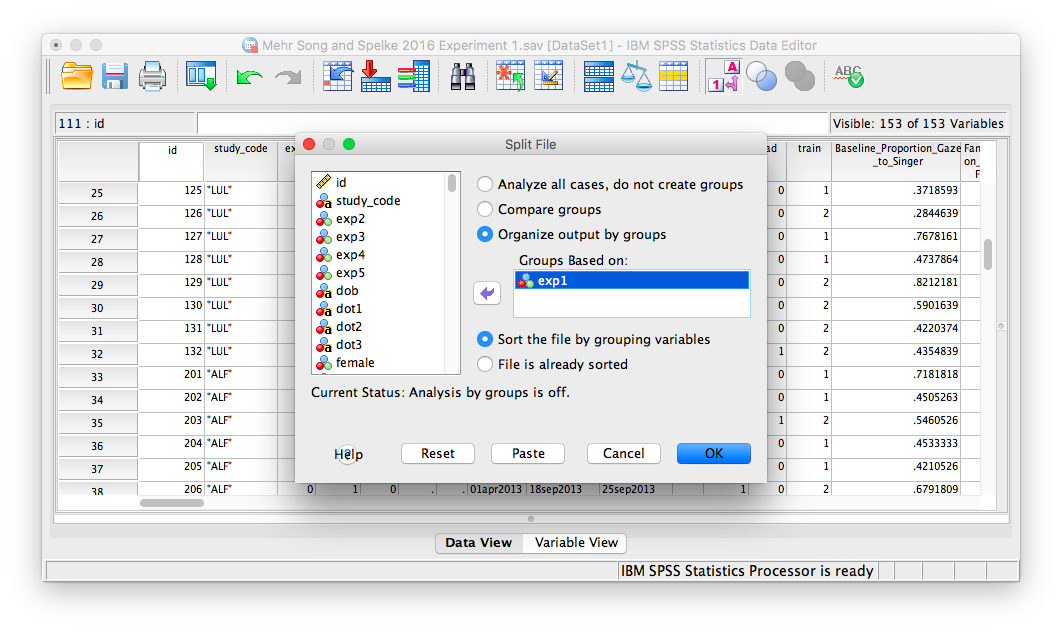 Click OK. SPSS will generate an output window to confirm you have split your file. In order to run the t-test, go to the Analyze menu, then choose Compare Means and then One-Sample T-test:
Click OK. SPSS will generate an output window to confirm you have split your file. In order to run the t-test, go to the Analyze menu, then choose Compare Means and then One-Sample T-test:
This will open up a window in which you will specify which variable contains the relevant sample data. Remember, we are interested in the variable labeled Baseline_Proportion_Gaze_to_Singer, so let’s choose this variable from the list on the left and move it to the right-hand field using the arrow.
Next, make sure to change the value in the field labeled “Test Value” to the mean to which you are comparing the sample. Since we are comparing our sample’s proportions to the proportion that represents equal time spent looking at both people in the video, we are going to use .5 as our test value. Enter this number in the appropriate field. Your window should look like this:
Now, click OK. SPSS will produce several output tables; some for exp1 = 0 (these are the infants not included in experiment 1) and for exp = 1 (for the infants included in experiment 1–this is the one we want!), as follows:
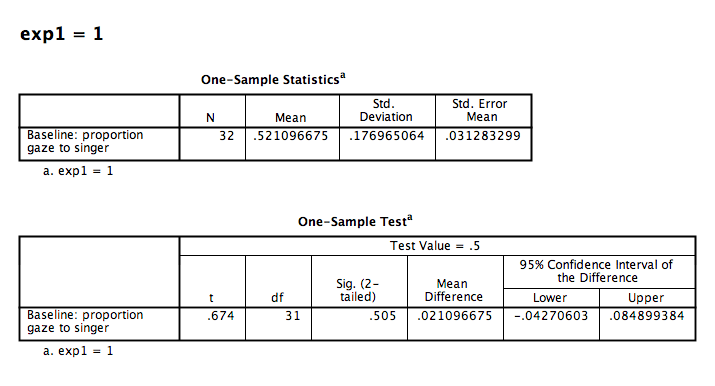
The first table contains descriptive statistics related to the sample. We can see from this table that the average proportion of time spent looking at the person who would later be the familiar song singer is .521. This is very close to .50.
The second table contains the information resulting from our t-test: The t-statistic calculated is .674, with 31 (N-1) degrees of freedom. The p-value is listed under “Sig.”. The fact that this value is not less than our alpha level (set at .05) means we fail to reject the null hypothesis. In other words, the proportion of time infants spent looking at the singer was not different from .50. We might formally words this as follows:
During the baseline condition, the mean proportion looking time toward the singer was .52, and was not significantly different from .5, according to a one-sample test, t(31) = .67, p = .505.
6.6.3 Performing a paired-samples t-test
In this example, we will be comparing data from two samples taken from the same individuals. In the same data file as above, we have two variables named Baseline_Proportion_Gaze_to_Singer and Test_Proportion_Gaze_to_Singer. These variables represent the proportion of time spent looking at the familiar song singer at baseline, and then again in the test phase (after the 1-2 week period in which infants have been familiarized with the song). Because each infant was measured once (baseline), and then re-measured again (test), we will use a paired-samples t-test.
Let’s continue with the split file we used in the previous example. In order to run the paired-samples t-test, go to Analyze, then Compare Means, then Paired-Samples T-test...
A window will appear with a list of all variables in a field on the left. We must choose the two variables that contain our data: Baseline_Proportion_Gaze_to_Singer and Test_Proportion_Gaze_to_Singer. Move these into the right-hand field individually using the arrow. Make sure that they appear next to each other in the right-hand field, as follows:
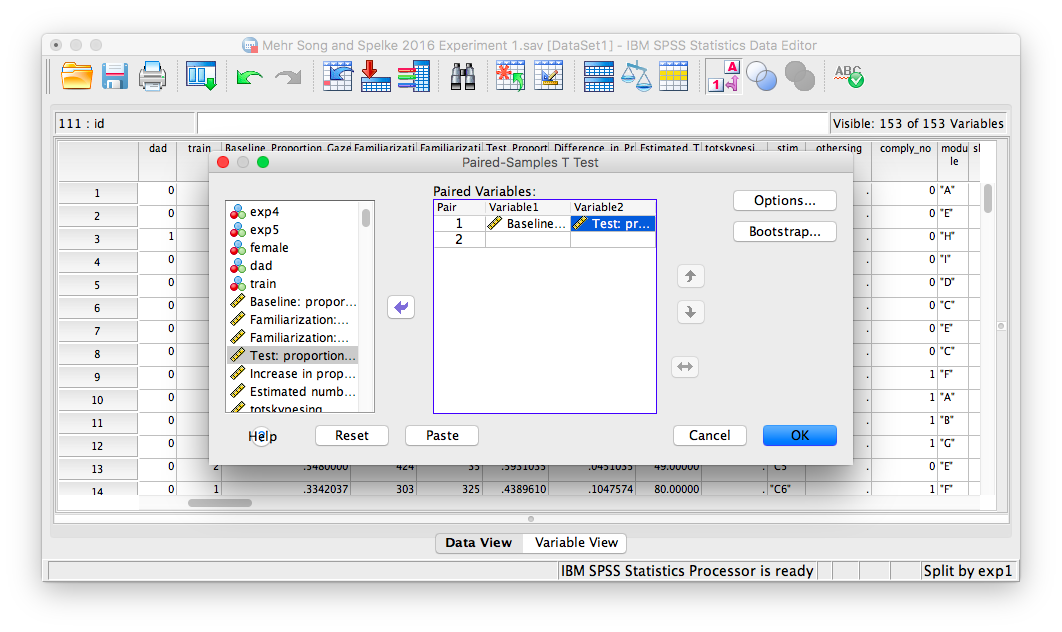
Click OK, and SPSS will produce several output tables. Remember, we’re only choosing the tables for exp1 = 1 (this includes only the 32 infants in experiment 1). The tables are as follows:
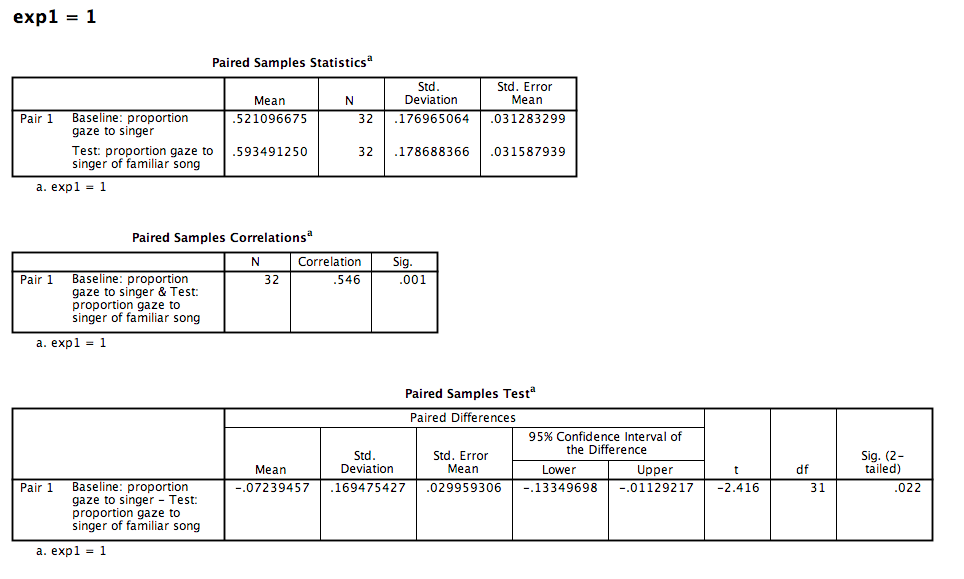
The paired-samples t-test produces a t-value, degrees of freedom (N-1), and a p-value. You can interpret these values the same way as in the previous example.
During the baseline condition, The difference between Infants’ mean proportion looking time toward the singer at baseline and the test phase was -.072, and was significant according to a paired-samples t-test, t(31) = -2.416, p < .05.
6.6.4 Graphing your results
In order to visualize the difference between means (for a paired-samples t-test, in this case), it is most appropriate to create a bar chart, or bar plot. Because our two conditions (baseline and test) are categorical, discrete (and not continuous) variables, this type of chart is most appropriate. Let’s begin by going to Graphs, then Chart Builder…
The Chart Builder window will open and look like this:
We are going to choose a simple bar chart, which is represented by the bar icon at the top left of the set of chart options. Click on this icon and drag it into the chart window as follows:
 Once you do this, your window should look like this:
Once you do this, your window should look like this:
From here, you must indicate which variables should be included in the chart on the y-axis. We will first take the Baseline_Proportion_Gaze_to_Singer variable, found in the list on the left of the window, and drag it to the y-axis in the chart window. You will see that the y-axis area will highlight with a red border when you do this.
Now, take the next variable, Test_Proportion_Gaze_to_Singer, and drag it over the same y-axis title, but this time aim for the very top of the variable field. You will know you’re doing it right when a red plus sign appears in this area as you hover:
Drop this variable into this field once you see the plus sign. A window will pop us asking if you want both variables on this axis. Click OK.
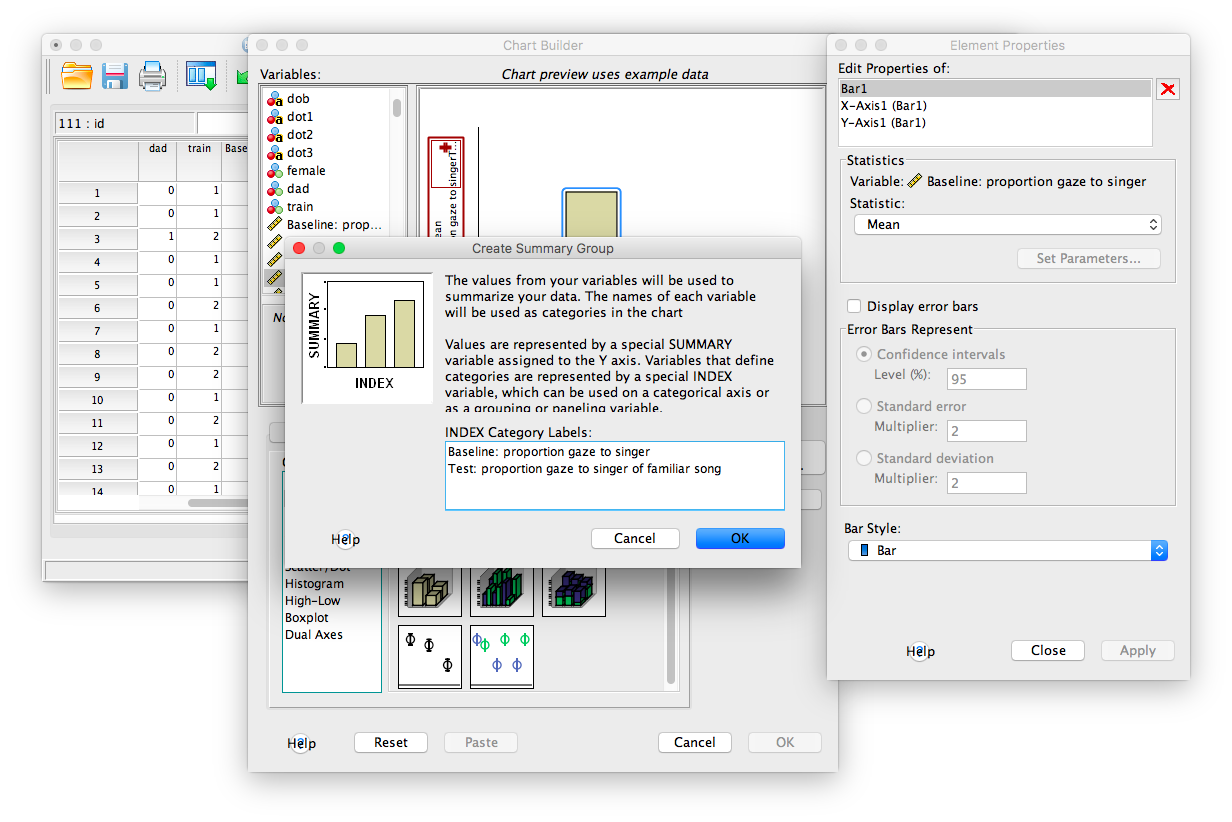
The result will look like this (both variables’ means, baseline and test, appear in the chart).
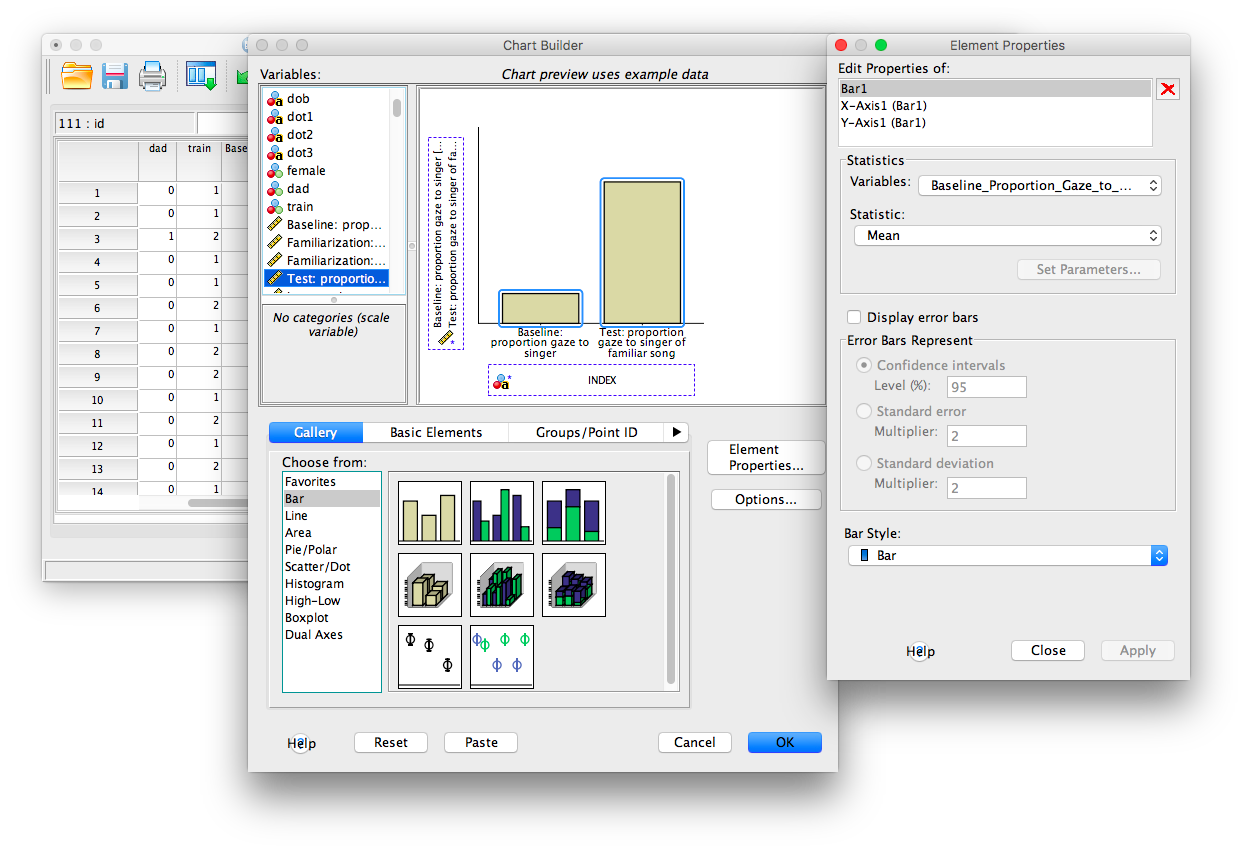
From here, you can customize the appearance of the graph. One thing we will do is add Error Bars. Find the window to the right of the main chart builder window, and select Error Bars. You will have the option to select Confidence Intervals, Standard Error, etc. Choose Standard Error and set the Multiplier to 2. Click Apply.
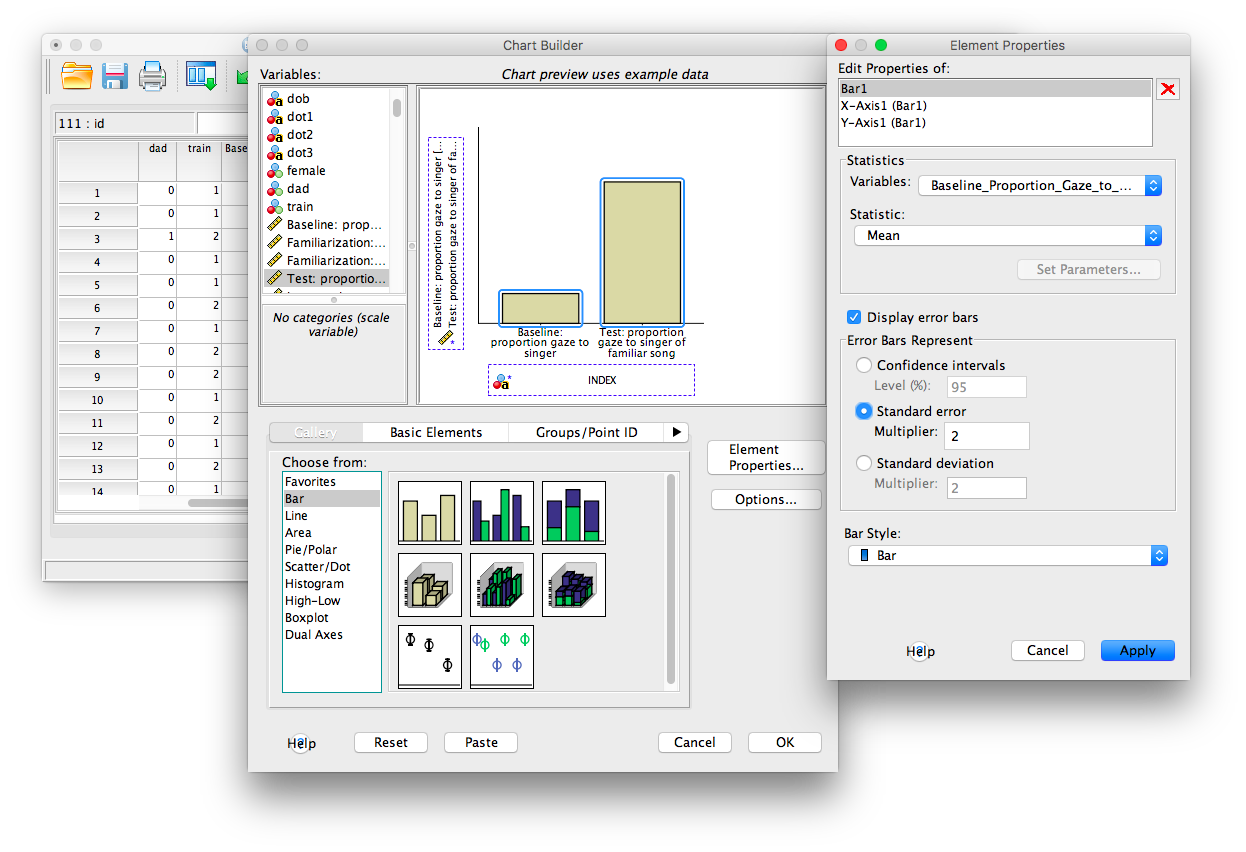
Now, you should be able to see the bars in the chart builder window.
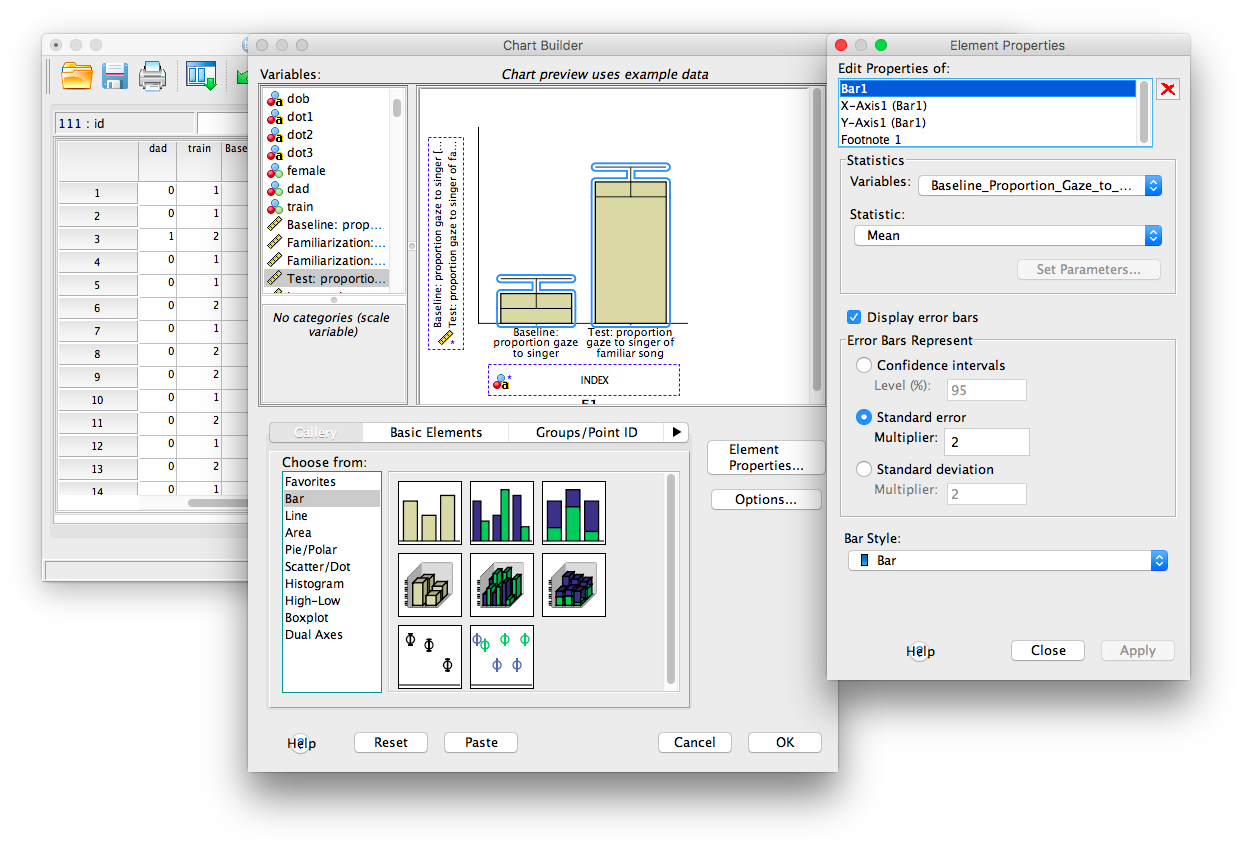
If you are satisfied with the chart, click OK and it will appear in an SPSS output window:
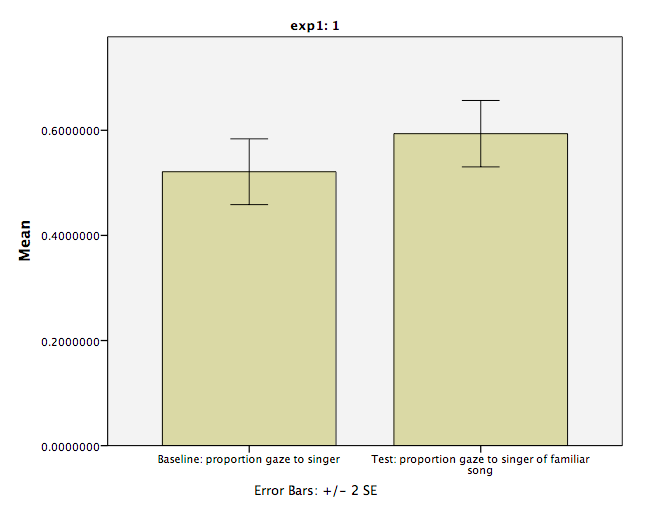
6.6.5 The relationship between the one-sample and the paired-samples t-test
This section is dedicated to demonstrating that the one-sample and paired-samples t-tests are almost the very same thing. In order to understand this, we must reframe how we think about the paired-samples t-test. We typically consider it a comparison between two samples in which observations have been repeated (like in a before-after scenario, for example). We can also think of the paired-samples t-test as testing the DIFFERENCE scores between two conditions. If the difference between two conditions is 0, then there is no difference, or there is no effect of the independent variable. If the difference is non-zero, then we can say there IS a difference.
Thus, the paired-samples t-test is exactly the same as the one-sample t-test if we consider it as a comparison of the mean DIFFERENCE score to 0. Let’s demonstrate this using SPSS.
We’ll continue using the same data as above. Specifically, locate the variable named Difference_in_Proportion_Looking. This variable contains the difference score between the baseline and test conditions for each infant. We’re going to treat this as our one sample (as in the one-sample t-test), and we’ll be comparing it to a mean of 0. Remember also that our file is still split so we can do analyses on only those individuals in experiment 1.
Let’s begin. Go to Analyze, then Compare Means, then One-Sample t-test…
A window will appear. Move the variable of interest, Difference_in_Proportion_Looking, into the “Test Variable(s)” field. Below that, make sure to enter 0 in the “Test Value” field.
Then click OK. SPSS will generate several tables in the output window. Make sure to find the tables associated with exp1 = 1. They should look like this:
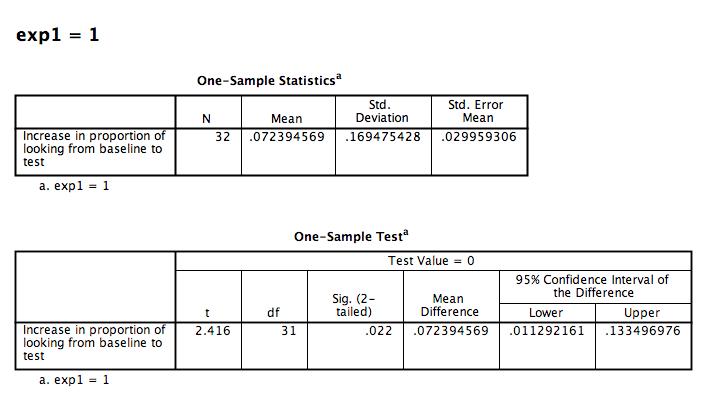
You will see that the t-statistic and p-value are identical to the ones obtained when we conducted a paired-samples t-test. Therefore, a paired-samples t-test conducted on two samples is equivalent to a one-sample t-test conducted on the difference scores (calculated on the two samples) compared against 0.
Nota Bene: You will see that in the previous paired-samples t-test we obtained a t-statistic of -2.416, but here the t-statistic is positive. This difference comes from the fact that SPSS automatically subtracts the later-occuring variable in your spreadsheet from the earlier-occuring one. If your variables were ordered differently, you would obtain a positive t-statistic as well. In other words, the sign does not matter; it results from the order of the variables.
6.6.6 Practice Problems
Use the data file from this lab tutorial to test whether the number of frames the baby spent gazing at the familiar song is significantly different than the number of frames spent gazing at the unfamiliar song (use alpha = .05). Report your results in proper statistical reporting format.
Graph this result (including 1 SEM error bars) as a bar graph.
Compute a new variable representing the difference in number of frames the baby spent gazing between the familiar and unfamiliar song conditions. Test this difference score against a mean of 0 (use alpha=.05). Report your results in proper statistical reporting format.
6.7 JAMOVI
How to do it in JAMOVI