Analysis E1A Inner Speech Talk and Type
Matt
5/14/2019
E1A_Analysis.RmdE1A IKSI Analysis
#load E1A data
E1_data <- talk_type_E1A_data
# IKSI analysis
E1_data <- E1_data %>%
mutate(subject = as.factor(subject)) %>%
filter(errors == 1,
iksis < 5000,
LetterType != "Space") %>%
group_by(subject,linguistic_unit,LetterType) %>%
summarise(mean_iksi = mean(modified_recursive_moving(iksis)$restricted),
prop_removed = modified_recursive_moving(iksis)$prop_removed)
E1_aov_out <- aov(mean_iksi ~ linguistic_unit*LetterType +
Error(subject/(linguistic_unit*LetterType)), E1_data)
knitr::kable(xtable(summary(E1_aov_out)))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 39 | 1474756.256 | 37814.2630 | NA | NA |
| linguistic_unit | 1 | 76739.011 | 76739.0113 | 24.891295 | 0.0000130 |
| Residuals | 39 | 120235.666 | 3082.9658 | NA | NA |
| LetterType | 1 | 151196.259 | 151196.2589 | 22.284563 | 0.0000301 |
| Residuals | 39 | 264607.123 | 6784.7980 | NA | NA |
| linguistic_unit:LetterType | 1 | 1547.208 | 1547.2079 | 3.083524 | 0.0869404 |
| Residuals | 39 | 19568.881 | 501.7662 | NA | NA |
E1A_iksi_table <- E1_data %>%
group_by(linguistic_unit,LetterType) %>%
summarize(mIKSI = mean(mean_iksi),
sem = sd(mean_iksi)/sqrt(length(mean_iksi)))
levels(E1A_iksi_table$linguistic_unit) <- c("Say Letter", "Say Word")
E1A_graph_iksi <- ggplot(E1A_iksi_table, aes(x=linguistic_unit,
y=mIKSI,
group=LetterType,
fill=LetterType))+
geom_bar(stat="identity",position="dodge")+
geom_errorbar(aes(ymin=mIKSI-sem,
ymax=mIKSI+sem), width=.1,
linetype="solid", position=position_dodge(.9))+
scale_fill_grey(start = 0.6, end = 0.8, na.value = "red",
aesthetics = "fill")+
theme_classic(base_size=12)+
theme(legend.position = "top",
legend.title = element_blank())+
ylab("Mean IKSI (ms)")+
xlab("Linguistic Unit")
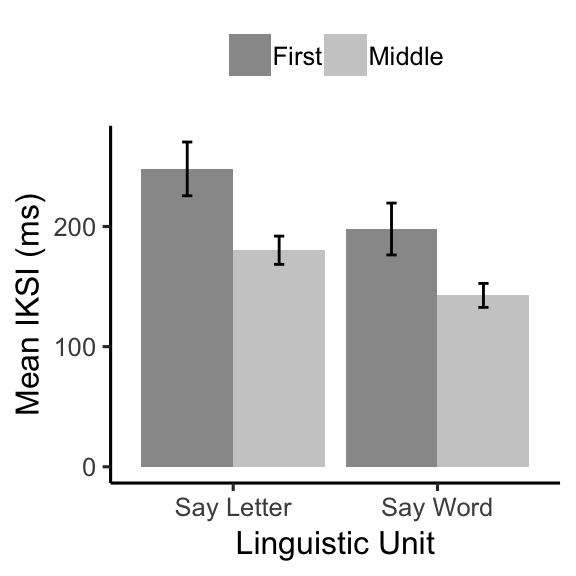
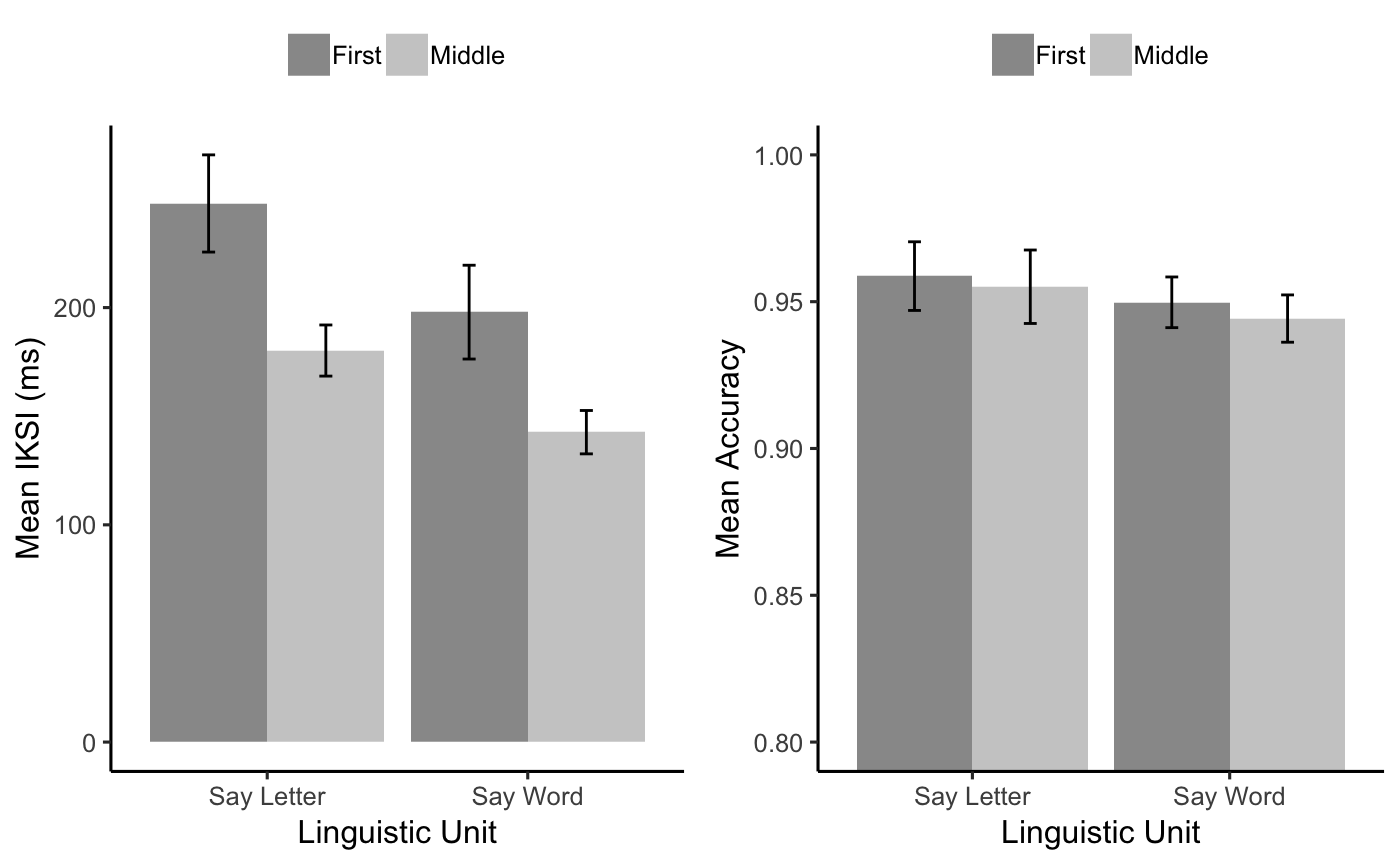
knitr::kable(E1A_iksi_table)| linguistic_unit | LetterType | mIKSI | sem |
|---|---|---|---|
| Say Letter | First | 247.9339 | 22.368227 |
| Say Letter | Middle | 180.2336 | 11.767037 |
| Say Word | First | 197.9142 | 21.590340 |
| Say Word | Middle | 142.6526 | 9.982549 |
accuracy
# Accuracy
E1acc_data <- talk_type_E1A_data
E1acc_data <- E1acc_data %>%
mutate(subject = as.factor(subject)) %>%
filter(LetterType != "Space") %>%
group_by(subject, linguistic_unit, LetterType) %>%
summarise(mean_acc = mean(errors))
E1acc_aov_out <- aov(mean_acc ~ linguistic_unit*LetterType + Error(subject/(linguistic_unit*LetterType)), E1acc_data)
E1acc_apa_print <- apa_print(E1acc_aov_out)
E1acc_means <- model.tables(E1acc_aov_out,"means")
knitr::kable(xtable(summary(E1acc_aov_out)))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 39 | 0.4066274 | 0.0104263 | NA | NA |
| linguistic_unit | 1 | 0.0039057 | 0.0039057 | 0.6985677 | 0.4083570 |
| Residuals | 39 | 0.2180470 | 0.0055909 | NA | NA |
| LetterType | 1 | 0.0008383 | 0.0008383 | 1.0114875 | 0.3207462 |
| Residuals | 39 | 0.0323229 | 0.0008288 | NA | NA |
| linguistic_unit:LetterType | 1 | 0.0000369 | 0.0000369 | 0.0807627 | 0.7777700 |
| Residuals | 39 | 0.0178246 | 0.0004570 | NA | NA |
E1A_acc_table <- E1acc_data %>%
group_by(linguistic_unit,LetterType) %>%
summarize(mAcc = mean(mean_acc),
sem = sd(mean_acc)/sqrt(length(mean_acc)))
levels(E1A_acc_table$linguistic_unit) <- c("Say Letter", "Say Word")
E1A_graph_acc <- ggplot(E1A_acc_table,
aes(x=linguistic_unit,
y=mAcc,
group=LetterType,
fill=LetterType))+
geom_bar(stat="identity",position="dodge")+
geom_errorbar(aes(ymin=mAcc-sem,
ymax=mAcc+sem), width=.1,
linetype="solid", position=position_dodge(.9))+
scale_fill_grey(start = 0.6, end = 0.8, na.value = "red",
aesthetics = "fill")+
theme_classic(base_size=12)+
theme(legend.position = "top",
legend.title = element_blank())+
ylab("Mean Accuracy")+
xlab("Linguistic Unit")+
coord_cartesian(ylim=c(.8,1))
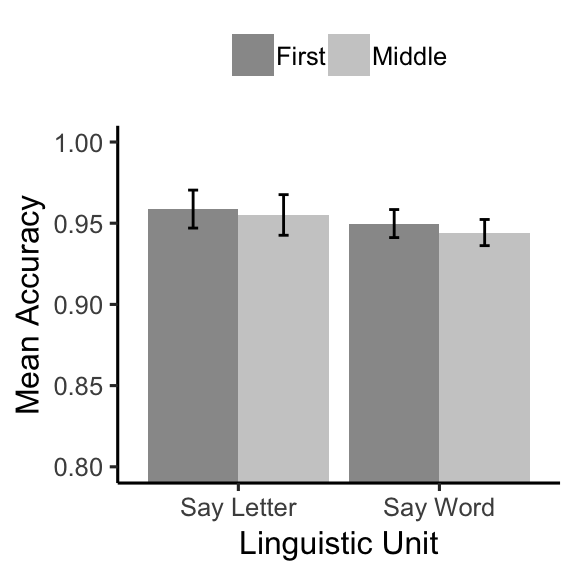
knitr::kable(E1A_acc_table)| linguistic_unit | LetterType | mAcc | sem |
|---|---|---|---|
| Say Letter | First | 0.9587045 | 0.0116924 |
| Say Letter | Middle | 0.9550872 | 0.0125089 |
| Say Word | First | 0.9497838 | 0.0086318 |
| Say Word | Middle | 0.9442452 | 0.0080552 |
Demographic information
E1A_dmg <- talk_type_E1A_dmg
proportion_word <- E1A_dmg %>%
group_by(InnerVoice) %>%
summarize(p_word = length(InnerVoice)/dim(E1A_dmg)[1])
inner_voice_props<-c(
round(proportion_word[proportion_word$InnerVoice=="Words",]$p_word, digits=2),
round(proportion_word[proportion_word$InnerVoice=="Letters",]$p_word,digits=2),
round(proportion_word[proportion_word$InnerVoice=="undefined",]$p_word,digits=2))