Typing and Talking: draft in progress
Matthew J. C. Crump
1,2mcrump@brooklyn.cuny.edu
Nicholaus Brosowsky
2Lawrence Behmer
1Talk_typing_draft.RmdAbstract
Enter abstract here. Each new line herein must be indented, like this line.People have the ability to construct ideas and optionally turn them into actions. For example, people can think about an idea, and then decide whether to say the idea out loud in the form of a sentence. The control procesess responsible for translating ideas into action in language production are not fully understood. In particular, we suggest that multi-threading abilities are one aspect of the translation process that is not well understood. We borrow the term mult-threading from computing, where it refers to the ability of a central processing unit to make use of a common code at one level, to control the output of different threads at other levels. An example of multi-threading in language production is the ability to produce language in different formats, such as speaking out loud, or writing or typing. We investigate the general idea that common word-level linguistic codes used for speech act as inputs to control manual keystroke during typing.
Hierarchical control and typing
Typing is assumed to be controlled by hierarchically nested control loops (Logan and Crump 2011). The outer loop relies on language comprehension and production to turn ideas into words and sentences. Word level-representations are then sent as goals to an inner loop that controls individual finger movements to individual keystrokes for each letter in a word.
The two loops are informationally encapsulated modules (Fodor 1983), and the outer loop does not know the details of how the inner loop accomplishes keystrokes (Logan and Crump 2009; Liu, Crump, and Logan 2010). However, the two loops must nevertheless be coordinated to accomplish accurate typing. Coordination is theorized to be accomplished by intermediate word-level representations. In other words, the tacit assumption is that multi-threading enables word production for typing to be controlled by the same word-level codes used for speaking.
These ideas have been instantiated by formal computational models of typing in different ways. For example, in Rumelhart and Norman (1982) typing model, word representations cause the parallel activation of letter units in a response scheduling buffer, which then controls individual keystrokes for all letters in the word. More recently, Logan (2018) showed that general memory process could use word-level representations to control the sequential execution of letter-level actions by a context, retrieval, and updating process (CRU). Although both models explain the process of serial ordering by different mechanisms, they commonly rely on higher level word-level codes to trigger lower level actions at the keystroke level.
Evidence for word-level representations in typing
Several line of evidence are consistent with word-level representations from the outer loop providing control functions over inner loop keystroke sequencing processes. We describe the evidence, and then consider whether the word-level representations controlling typing are the same one used for controlling speech, which would suggest that language production can output actions in a multi-threaded fashion, with threads for speech and typing.
Typing speed is fastest for words and decreases as letter strings approach random orders (Shaffer and Hardwick 1968; Behmer and Crump 2017). This finding is consistent with the idea that typists use word-representations to control fluent typing, and that typing becomes disfluent when word-representations (e.g., for random strings) are unavailable. At the same time, the differences between typing words and non-word strings that approximate the structure of words to various degrees could reflect a frequency sensitive learning process (Logan 1988) that operates at the letter level, or n-gram level (e.g., letter bigrams or trigrams).
First-letter and mid-word slowing phenomenon (Ostry 1983) in typing show that the first letter in a word is typed more slowly than the remaining letters, and the middle letter in a word is generally typed more slowly than the surrounding letters. First letter slowing could reflect the planning or buffering time necessary for the outer loop to construct and send a word-level represention to the inner loop. Mid-word slowing could reflect a similar planning process operating at the level of syllables (Massaro and Lucas 1984; Pinet, Ziegler, and Alario 2016; Will, Nottbusch, and Weingarten 2006), which appear in the middle of words. Alternatively, Crump, Lai, and Brosowsky (n.d.) proposed that first and middle letter slowing could be explained by letter-level informational uncertainty, as a function of letter position, word length, and previous letter contexts. Although the found that letter uncertainty explained a large portion of the variance in keystroke times for letters in the contexts, they also found that first letter keystroke times were longer than would be expected on the basis of letter uncertainty alone. They concluded that first-letter slowing reflects a combination of planning time and learned sensitivity to the predictability of letters in those contexts.
Last, Crump and Logan (2010) showed that words and nonwords differentially prime their constituent letters. They presented a word or non-word as a prime, and then had subjects respond to a subsequent letter probe. Word string primes facilitated letters for all positions in a word, compared to letters not in the word. However, non-word string primes only showed facilitation for letter probes from the first position in the string. This finding suggests that a word-level representation plays a role in facilitating the production of all of its constituent letters.
Common codes and multi-threaded language production
The output of language production can take several forms, including speaking (out loud, or silenty using inner voice), writing, typing, and signing. Each output modality requires specific motor control operations for successful action production.Additionally, people appear capable of producing language in multiple modes at the same time. For example, I am saying these words using my inner voice while my fingers type the letters. The control structures translating higher-level ideas into lower-level, modality specific motor output streams are not well-understood; especially, when multiple output streams are available potentially working simultaneously.
One outer loop to many inner loops
We consider some ways in which the hierchical control assumptions from the two-loop theory of typing might be generalized to account for multiple, simultaneous modes of language production. First, a single outer loop might provide common word-level representations sent to multiple inner loops to control action within each output mode. We would also assume that inner loops for talking, writing, typing, or signing, would depend on practice, and would only be highly automatized for highly practiced modes of communication. In this way, an inner loop for speech production and typing production might capable of running in parallel, while being served the same word-level instructions from the outer loop. This one-to-many account raises further questions about the serial versus parallel nature of the inner loops. For example, if the an inner loop for speech is fully autonomous from an inner loop for typing, then they might be expected to run simultaneously without one process interfering with another. At the same, if both loops are being triggered by shared word-level codes, then manipulations that influence how the outer loop produces word representations for word production should have a cascading and common influence on speech and typing production. For example, having typists speak one word while typing another word might be expected to disrupt typing ability, because interference between word-level representations in the outer-loop created by the demand to speak one word, could interfere with the demand to type a different word.
Many outer loops to many inner loops
The nature of the outer loop in the two loop theory of typing is not well understood or explained. This loop is granted the extraordinary ability to generate ideas and translate them into sentences and words. It is unclear whether the outer loop should be thought of as a singular or multi-loop process. For example, if the outer loop could generate multiple ideas at the same time, each idea might be thought of as an independent loop capable of interfacing with a particular inner loop for output. In this case, a person might be able to use one outer loop to construct a word to control speech prodution, and another outer loop to construct a different word to control typing production. This many-to-many loop framework raises similar questions about the capacity for independent and simulatenous loop operation.
to what extent do people have the ability to control language production in a multi-threaded fashion, allowing multiple inner loop modes of language production to proceeed from commands given by a single higher-order outer loop?
There are several open questions about the potential constraints on multi-threaded language production. One possibility is that each inne
This effect of string structure could simply reflect familiarity and prior experience with typing words compared to random letter sequences, but could also be driven by string pronounceability. For example, typing speed is also influenced by syllabic structure, with faster interkeystroke times for letters within versus between syllables in a word. Word-level representations may also have a special status in activating all constituent letters in parallel compared to non-words which do not activate all letters in a sequence (). Finally, lexical structure at the level of bigrams appears to influence the spatial precision with which typists locate keys during typing (). This evidence is consistent with the idea that typists use verbal codes in a straightforward manner during typing, by concurrently using their inner voice (and perhaps sometimes speaking out loud) to say the same words they are typing.
Other work looking at dual-task interference in typing suggests that fast and accurate typing may not necessarily depend on using verbal codes. Protection from dual-task interference is often interpreted as evidence that is a skill is highly automatized, and typing in general appears to be highly automatized. For example, typing speed in a dual task-condition to identify auditory tones with a foot-pedal was only 4ms slower than normal typing. Remarkably, Shaffer (1975) showed that typing speed was mostly unaffected under concurrent task demands to recite an unrelated nursery rhyme while typing. However, typing speed was slowed substantially when typists copied spoken words while simultaneously reading unrelated visually presented text. And, these data were collected only from a single skilled typist, and whether the result is generalizable remains unclear. On the one hand, if the same verbal codes used for speech are used for typing, it is surprising that a typist could easily type one set of words while saying another set of words out loud without interference. On the other hand, interference appears to depend on the details of how verbal codes are used, as interference was observed when typists attempted to read unrelated text while copying spoken words.
The purpose of the present work is to clarify whether and how typists use verbal codes during typing. One possibility is that verbal codes for speech do not participate directly in the control of keystrokes for typing. On this view, typing could be considered a highly automatized and modularized skill that runs largely independently from other language production processes. Although speaking and typing may often go hand in hand, as many typists report silently voicing the words they are typing while they produce text (see Experiment 1), overt or covert speech production during typing could be carried out independently and in parallel with the motor movements required for typing. Another general possibility is that typists co-opt existing speech production processes during typing, so that normal typing is deeply connected at some level to a common language production process. We test these two general ideas in a series of related typing tasks that manipulate what typists say while they are typing. A central empirical aim was to tax concurrent speech production processes with reciting relevant or irrelevant content during copy-typing. In this way, we could establish boundary conditions for observing interference (or the lack thereof) from speech production on keystroke production.
In Experiment 1a and 1b we had typists speak the words or letters they were typing either silently or out loud. This experiment tested the idea that typists use verbal codes at the word rather than letter level during typing. The remaining experiments investigated the extent to which typing performance can be impaired by disrupting normal speech production. Experiment 2 measured copy-typing performance across several verbal suppression conditions where typists were instructed to repeat words or letter (unrelated to the text they were copying) out loud as they typed. Experiment 3 measured copy-typing performance under conditions of delayed auditory feedback, which is known to disrupt fluent speech.
Experiment 1a and 1b: Speaking words or letters during typing
The immediate goal of typing is to produce letters in the correct order during word and sentence production. Based on the idea that verbal codes are used during typing, we assumed that typists routinely verbalize, either covertly or overtly, aspects of the letters they are typing. For example, as I type this sentence, my subjective experience is that I silently voice the words I am typing. In Experiment 1a, we asked typists recruited online from Amazon’s mechanical turk to copy-type a paragraph under two conditions to silently voice each word as they typed, or silently voice each letter as they typed. To gain an understanding of the subjective experience of using the inner voice during typing, we also asked typists to report what their inner voice usually says during typing (e.g., words, letters, both, or none). Because we had no way of controlling whether our subjects adopted our instructions, we conducted Experiment 1b as a lab-based replication and extension of Experiment 1a. In Experiment 1b, subjects copied five paragraphs. The first paragraph provided a baseline and involved only the instruction to copy-type as quickly and accurately as possible. Across the remaining four paragraphs we manipulated whether subjects spoke out loud or silently to themselves, combined factorially with whether they spoke words or letters during typing. If typists use verbal codes at the word level during typing, then we expected that typing speed should be faster when subjects were instructed to say words rather than letters as they typed.
Methods
Subjects
In experiment 1a, 50 subjects were recruited from AMT and compensated $0.25 for participating in the approximately 5 minute task. 40 subjects completed the task and were included in the analysis. In experiment 1b, 16 subjects were recruited from the undergraduate population at Brooklyn College, and received course credit for their participation. One subject was not included in the analysis because they repeatedly typed “asdf”, rather than completing the task.
Apparatus & Stimuli
For experiment 1a, typing tests were programmed for the online environment using HTML and JavaScript and conducted in subjects’ web-browsers. For experiment 1b, typing tests were conducted on an iMac (21" screen) controlled by LIVECODE software. Typing responses were registered on a standard QWERTY keyboard. Each paragraph in the typing task involved copy-typing short paragraphs (~115 words length), taken from Logan and Zbrodoff (1998).
Design and Procedure
During the task, participants were shown each paragraph in a text box. Paragraph text was black and presented in 14pt, Helvetica font. In general, participants were instructed to begin typing with the first letter in the paragraph. Correctly typed letters turned green, and typists could only proceed to the next by typing the current letter correctly. For each of the different typing conditions, subjects were presented with the following instructions.
For experiment 1a, the instructions read: This experiment tests how you your inner voice influences your typing ability. When you type this paragraph, use your inner voice to say each word (or letter in the letter condition) that you type. At the beginning of the experiment, subjects were also asked to choose whether they use their inner voice during typing to speak either words or letters.
For experiment 1b, in the speak aloud condition, the instructions read: When you type this paragraph, speak aloud each word (or letter in the letter condition) that you type. In the inner voice condition, the instructions were identical to experiment 1a. At the beginning of the experiment, subjects were given a short questionnaire about how they use their inner voice during typing. The questionnaire stated “People have the ability to use their inner voice to speak silently to themselves. We are interested in how you use your inner voice while you are typing. Please estimate the percentage of times that your inner voice is engaged in each of the following tasks while typing, and make sure your numbers add up to 100.”. The four tasks were: a) inner voice is silent, b) inner voice speaks words that you are typing, c) inner voice speaks letters that you are typing, d) inner voice speaks other words or letters that you are not typing.
Results
Experiment 1a
For each subject, we applied the following pre-processing steps. We included IKSIs only for successively correct keystrokes and lower case letters. Outlier IKSIs were removed for each subject on a cell-by-cell basis using the Van Selst and Jolicoeur (1994) non-recursive moving criterion procedure, which eliminated approximately 0.05 of IKSIs from further analysis. An alpha criterion of .05 was set for all analyses.
Mean IKSIs for correctly typed letters were computed for each subject in each condition and submitted to a 2 (Linguistic Unit: Say Letters vs. Say Words) x 2 (Letter position: First letter vs. Middle Letter) repeated measures ANOVA. Mean IKSIs are displayed in Figure @ref(fig:E1Figure).
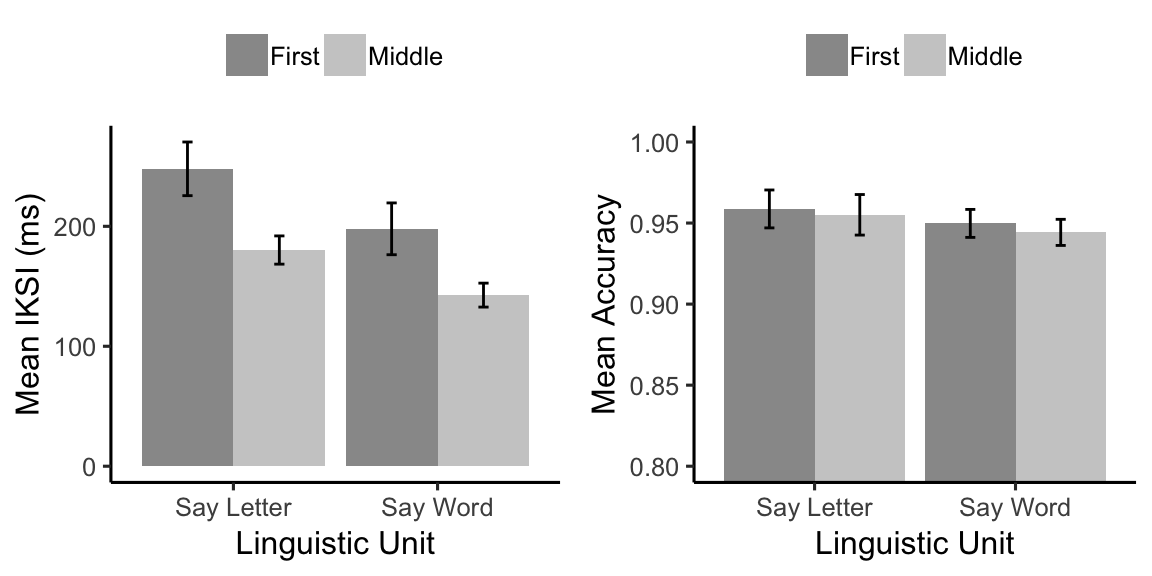
Mean interkeystroke intervals (IKSIs in ms) and mean accuracy as a function of linguistic unit condition (Say Word vs. Say Letter), and letter position in word (first letter vs. middle letter). Middle letters were any remaining letter in the word.
The main effect of the linguistic unit condition was significant, \(F(1, 39) = 24.89\), \(\mathit{MSE} = 3,082.97\), \(p < .001\), \(\hat{\eta}^2_G = .039\). Mean IKSIs were shorter when subjects were instructed to use their inner voice to say the words (170), rather than the letters (214) they were typing.
The main effect of letter position was significant, \(F(1, 39) = 22.28\), \(\mathit{MSE} = 6,784.80\), \(p < .001\), \(\hat{\eta}^2_G = .074\). Mean IKSIs were longer for letters in the first position (223), compared to letters in the other positions (161).
The interaction between linguistic unit and letter position did not meet the significance criterion, \(F(1, 39) = 3.08\), \(\mathit{MSE} = 501.77\), \(p = .087\), \(\hat{\eta}^2_G = .001\).
A corresponding 2x2 repeated measures ANOVA was conducted on the mean accuracies for typing letters in each condition. Mean accuracies are shown in Figure @ref(fig:E1Figure). Accuracy was uniformly high in all conditions, and there were no main effects or interaction.
Last, prior to the experiments subjects were asked if their inner voice usually thinks in words or letters when they type. The proportions of subjects reporting thinking in words, letters, or who did not answer were 0.9, 0.08, 0.02, respectively.
Experiment 1b
The same pre-processing rules were applied to the data. The outlier elimination procedure excluded an average of 0.06 observations from each condition. Mean IKSIs and accuracies for each condition are displayed in Figure @ref(fig:E1BFigure)
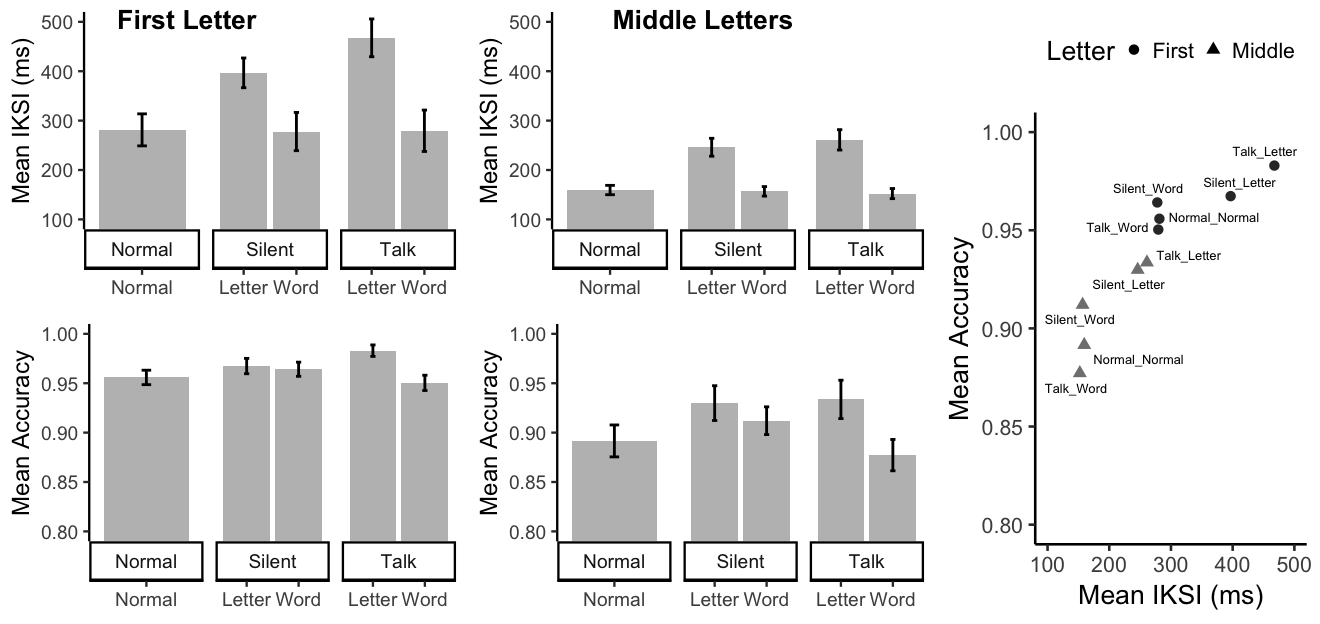
Mean IKSIs in milliseconds and mean accuracy for typing the first letter in a word, or all other letters (middle letters) for each of the five paragraph typing conditions. For each letter type, the scatterplot shows mean accuracy by mean IKSI for each typing condition.
First letter IKSIs
Mean correctly typed first letter IKSIs for each subject were submitted to a one-way repeated measures ANOVA.
The main effect of paragraph typing condition was significant, \(F(4, 56) = 14.49\), \(\mathit{MSE} = 7,884.78\), \(p < .001\), \(\hat{\eta}^2_G = .246\). Linear contrasts were constructed to interpret the major patterns. First, normal typing compared to silent-word and talk-word conditions were not different, \(M = -2.62\), 95% CI \([-42.41\), \(37.18]\), \(t(14) = -0.14\), \(p = .890\). The instruction to say each word (silently or out loud) while typing did not facilitate or interfere with first letter typing time compared to normal typing. One possibility is that normal typing typically involves saying words while typing, so the added instruction may be redundant with normal activity during typing.
Second, mean first letter IKSIs for silent-letter and talk-letter conditions were shorter than the other conditions, \(M = 152.63\), 95% CI \([83.40\), \(221.85]\), \(t(14) = 4.73\), \(p < .001\). The data clearly show that first-letter typing time increases when subjects say letters rather than words while typing. Finally, saying letters out loud appeared to slow down first-letter typing compared to saying letters silently, \(M = 70.87\), 95% CI \([3.02\), \(138.72]\), \(t(14) = 2.24\), \(p = .042\).
Middle letter IKSIs
A corresponding ANOVA was conducted on IKSIs for all correctly typed middle letters.
The main effect of paragraph typing condition was significant, \(F(4, 56) = 19.13\), \(\mathit{MSE} = 2,258.78\), \(p < .001\), \(\hat{\eta}^2_G = .442\). Mean middle letter IKSIs during normal typing were longer compared to silent-word and talk-word conditions, \(M = -4.92\), 95% CI \([-7.80\), \(-2.05]\), \(t(14) = -3.67\), \(p = .003\). Saying words silently or out loud appeared to facilitate typing speed by a small, yet detectable amount.
Mean IKSIs for silent-letter and talk-letter conditions were much longer than the other conditions, \(M = 97.40\), 95% CI \([54.38\), \(140.41]\), \(t(14) = 4.86\), \(p < .001\). But, there was no difference between the silent-letter and talk-letter conditions, \(M = 15.02\), 95% CI \([-17.25\), \(47.30]\), \(t(14) = 1.00\), \(p = .335\).
Accuracy
The analysis of accuracy showed a main effect of linguistic unit, \(F(1, 14) = 11.72\), \(\mathit{MSE} = 0.00\), \(p = .004\), \(\hat{\eta}^2_G = .076\). Subjects were more accurate when saying letters (0.95), than words (0.93 ms). The main effect of letter position was significant, \(F(1, 14) = 31.20\), \(\mathit{MSE} = 0.00\), \(p < .001\), \(\hat{\eta}^2_G = .229\). Subjects were more accurate for the first letter (0.97), compared to other letters (0.91). The main effect of voice was not significant, \(F(1, 14) = 2.33\), \(\mathit{MSE} = 0.00\), \(p = .149\), \(\hat{\eta}^2_G = .006\). These main effects were qualified by two-way interactions.
The interaction between voice and linguistic unit was significant, \(F(1, 14) = 5.12\), \(\mathit{MSE} = 0.00\), \(p = .040\), \(\hat{\eta}^2_G = .030\). The decrease in accuracy for saying words vs letters was larger when subjects spoke out loud, compared to speaking silently with their inner voice. The interaction between voice and letter position was significant, \(F(1, 14) = 4.69\), \(\mathit{MSE} = 0.00\), \(p = .048\), \(\hat{\eta}^2_G = .007\). The decrease in an accuracy for middle letters vs first letters was larger when subjects spoke out loud, compared to speaking silently. The interaction between linguistic unit and letter position was significant, \(F(1, 14) = 5.85\), \(\mathit{MSE} = 0.00\), \(p = .030\), \(\hat{\eta}^2_G = .010\). The decrease in accuracy for middle letters vs first letters was larger when subjects said the word rather than the letter they were typing. The three-way interaction was not significant, \(F(1, 14) = 0.32\), \(\mathit{MSE} = 0.00\), \(p = .579\), \(\hat{\eta}^2_G = .001\)
The mean responses for the inner voice questionnaire were that subjects’ inner voice was silent 3%, said words 69%, said letters 16%, or said unrelated words or letters 12% of the time during typing.
Discussion
The main finding from both experiments was that mean typing speed was much faster when subjects covertly or overtly said the words they were typing rather than the letters they were typing. The behavioral data was also supported by the questionnaire data which showed that most subjects claim to use their inner voice to say the words they are typing rather than say letters, unrelated words or letters, or nothing at all. This finding is consistent with the idea that verbal codes at the word level are important mediators of keystroke production during typing.
Experiment 2: Verbal Suppression
Verbal suppression techniques are commonly used in memory studies to prevent subjects from using their inner voice to verbally code and rehearse to-be-remembered information. The technique usually involves asking subjects to repeatedly recite a word or phrase out loud during the rehearsal period. As a result, verbal processes are occupied by the reciting the word, and presumed to be unavailable for rehearsing information in working memory. Experiment 2 asked whether similar verbal suppression techniques would also disrupt typing performance. We had subjects copy-type one of six paragraphs under one normal condition, and five verbal suppression conditions. Each verbal suppression condition had typists say words or letters out loud while they typed. These conditions included: a) repeating the word “the”, b) repeating the words Tuesday and Thursday, c) repeating the letters of the alphabet in order, d) repeating randomly chosen letters, and e) counting backwards from X.
Methods
Subjects
15 subjects were recruited from the undergraduate population at Brooklyn College, and received course credit for their participation.
Design and Procedure.
The same general typing test procedure from Experiment 1b was used, with the exception that typists copied six paragraphs. The instructions for each of the conditions were as follows:
Normal Typing instructions:
Say the instructions:
Say Tuesday/Thursday instructions:
Say alphabet instructions:
Say random letters instructions:
Count instructionResults
The same pre-processing rules were applied to the data. The outlier elimination procedure excluded an average of 0.06 observations from each condition. Mean IKSIs and accuracies for each condition are displayed in Figure @ref(fig:E2).
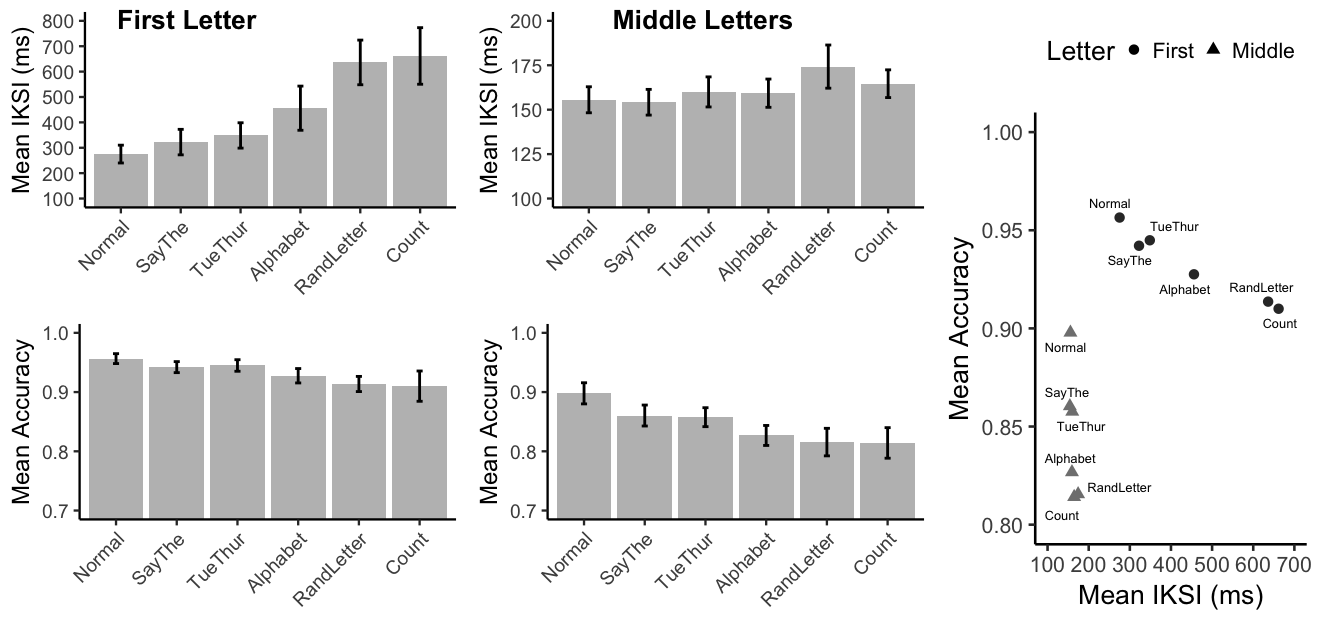
Mean IKSIs in milliseconds and mean accuracy for typing the first letter in a word, or all other letters (middle letters) for each of the six paragraph typing conditions. Note, the range of mean IKSIs for the middle letters is truncated to show differences between conditions. For each letter type, the scatterplot shows mean accuracy by mean IKSI for each typing condition.
First letter IKSIs
Mean correctly typed first letter IKSIs for each subject were submitted to a one-way repeated measures ANOVA. The main effect of paragraph typing condition was significant, \(F(5, 70) = 15.29\), \(\mathit{MSE} = 26,812.22\), \(p < .001\), \(\hat{\eta}^2_G = .223\). Linear contrasts were constructed to interpret the major patterns. First letter mean IKSIs during normal typing were not significantly different from the Say The, and Tuesday Thursday conditions, \(M = 60.30\), 95% CI \([-2.19\), \(122.79]\), \(t(14) = 2.07\), \(p = .057\). First letter mean IKSIs were longer when saying the Alphabet compared to Say The, and Tuesday Thursday, \(M = 120.46\), 95% CI \([22.72\), \(218.20]\), \(t(14) = 2.64\), \(p = .019\). Finally, first letter mean IKSIs were longest while saying Random Letters and Counting compared to the Alphabet condition, \(M = 193.02\), 95% CI \([76.60\), \(309.44]\), \(t(14) = 3.56\), \(p = .003\).
Middle letter IKSIs
Mean correctly typed middle letter IKSIs for each subject were submitted to a one-way repeated measures ANOVA. The main effect of paragraph typing condition was significant, \(F(5, 70) = 3.77\), \(\mathit{MSE} = 212.75\), \(p = .004\), \(\hat{\eta}^2_G = .041\). Middle letter mean IKSIs during normal typing were not significantly different from the Say The, Tuesday Thursday, Alphabet, and Counting conditions, \(M = 3.95\), 95% CI \([-0.66\), \(8.56]\), \(t(14) = 1.84\), \(p = .088\). Middle letter mean IKSIs were longer in the Random Letter condition compared to normal typing, \(M = 18.67\), 95% CI \([4.03\), \(33.31]\), \(t(14) = 2.74\), \(p = .016\).
Accuracy
Mean first letter accuracies for each subject in each condition were submitted to a one-way repeated measures ANOVA. The main effect of paragraph typing condition was significant, \(F(5, 70) = 3.00\), \(\mathit{MSE} = 0.00\), \(p = .016\), \(\hat{\eta}^2_G = .091\). Mean accuracy during normal typing was not different from the Say The and Tuesday Thursday conditions, \(M = -0.01\), 95% CI \([-0.03\), \(0.00]\), \(t(14) = -1.74\), \(p = .103\). Mean accuracy for the Alphabet, Random Letter, and Counting conditions was significantly worse compared to the former conditions, \(M = -0.03\), 95% CI \([-0.05\), \(-0.01]\), \(t(14) = -3.07\), \(p = .008\).
For middle letter accuracies, the main effect of paragraph typing condition was significant, \(F(5, 70) = 5.60\), \(\mathit{MSE} = 0.00\), \(p < .001\), \(\hat{\eta}^2_G = .138\). Mean accuracy during normal typing was not different from the Say The and Tuesday Thursday conditions, \(M = -0.04\), 95% CI \([-0.08\), \(0.00]\), \(t(14) = -1.91\), \(p = .077\). Mean accuracy for the Alphabet, Random Letter, and Counting conditions was significantly worse compared to the former conditions, \(M = -0.05\), 95% CI \([-0.08\), \(-0.03]\), \(t(14) = -4.24\), \(p = .001\).
Experiment 3: Delayed auditory feedback
Delayed auditory feedback is well known to disrupt speech; for example, when a speaker listens to their own voice on a short delay (100 to 300 ms) while speaking. Experiment 3 asked whether delayed auditory feedback would also disrupt typing performance. We had subjects copy-type paragraphs under normal and delayed auditory feedback conditions, which involved speaking the words being typed while hearing the spoken words on a brief auditory delay. If the same control processes responsible for speech are being used to support typing, we expected that delayed auditory feedback would disrupt both speech and typing performance.
Methods
Subjects
X subjects were recruited from the undergraduate population at Brooklyn College, and received course credit for their participation.
Results
The same pre-processing rules were applied to the data. The outlier elimination procedure excluded an average of NA observations from each condition. Mean IKSIs and accuracies for each condition are displayed in Figure @ref(fig:E3).
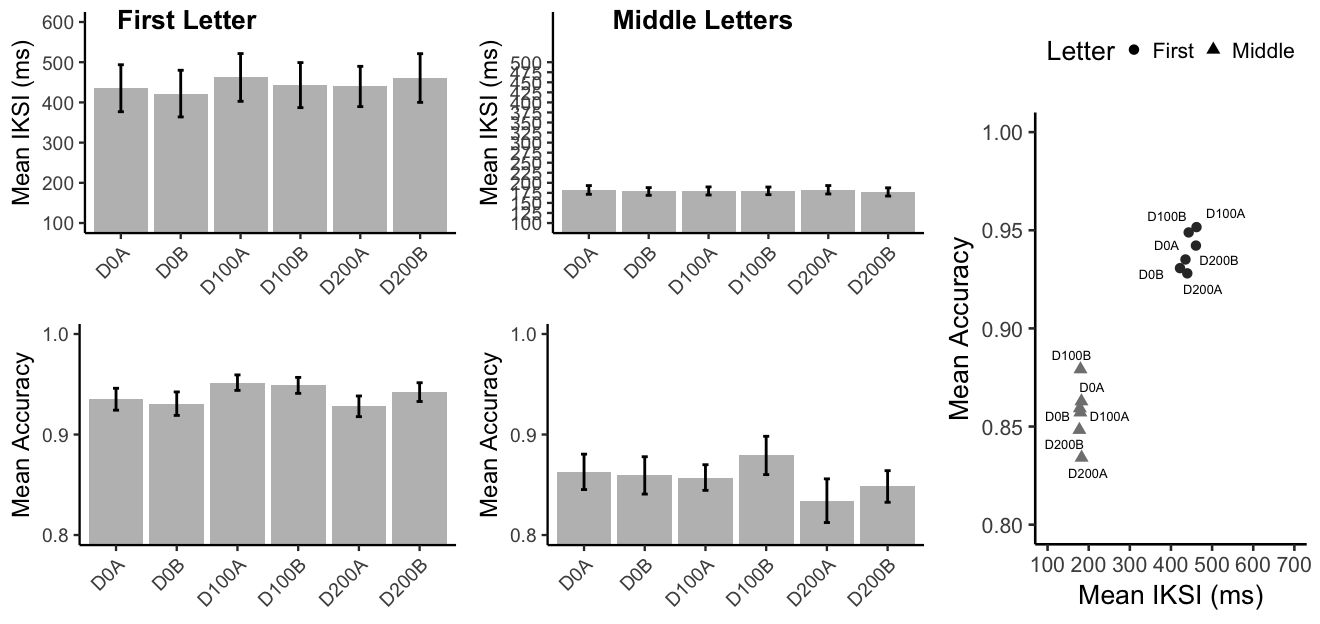
Mean IKSIs in milliseconds and mean accuracy for typing the first letter in a word, or all other letters (middle letters) for each of the delayedd auditry feedback conditins. For each letter type, the scatterplot shows mean accuracy by mean IKSI for each typing condition.
IKSIs
Mean correctly typed first letter IKSIs for each subject were submitted to a one-way repeated measures ANOVA. The main effect of paragraph typing condition was not significant, \(F(5, 85) = 1.71\), \(\mathit{MSE} = 2,502.92\), \(p = .142\), \(\hat{\eta}^2_G = .004\). Similarly, for the companion ANOVA for the middle letter IKSIs, the main effect of paragraph typing condition was not significant, \(F(5, 85) = 1.29\), \(\mathit{MSE} = 62.12\), \(p = .277\), \(\hat{\eta}^2_G = .002\).
Accuracy
Mean first letter accuracies for each subject in each condition were submitted to a one-way repeated measures ANOVA. The main effect of paragraph typing condition was significant, \(F(5, 85) = 2.72\), \(\mathit{MSE} = 0.00\), \(p = .025\), \(\hat{\eta}^2_G = .046\). Mean accuracy was higher for the 100 ms delay condition compared to the 0 ms delay condition, \(M = 0.02\), 95% CI \([0.00\), \(0.03]\), \(t(17) = 2.34\), \(p = .032\), and to the 200 ms delay condition, \(M = 0.02\), 95% CI \([0.00\), \(0.03]\), \(t(17) = 2.36\), \(p = .030\). Mean accuracy was not different for the 0 ms and 200 ms conditions, \(M = 0.00\), 95% CI \([-0.01\), \(0.01]\), \(t(17) = 0.40\), \(p = .698\).
For middle letter accuracies, the main effect of paragraph typing condition was significant, \(F(5, 85) = 2.67\), \(\mathit{MSE} = 0.00\), \(p = .027\), \(\hat{\eta}^2_G = .034\). Mean accuracy was not different for the 0 ms and 100 ms conditions, \(M = 0.01\), 95% CI \([-0.01\), \(0.03]\), \(t(17) = 0.70\), \(p = .493\). Mean accuracy was lower for the 200 ms delay condition compared to the 0 ms delay condition, \(M = -0.02\), 95% CI \([-0.03\), \(-0.01]\), \(t(17) = -2.88\), \(p = .010\), and to the 100 ms delay condition, \(M = -0.03\), 95% CI \([-0.05\), \(-0.01]\), \(t(17) = -2.75\), \(p = .014\).
General Discussion
Language production processes turn ideas into actions. For example, people use utterances and gestures to convey semantic meaning during conversation; to preserve ideas in different mediums, such as hand-writing, typewriting, and dictation; and to plan and guide cognition and behavior in general. In Vygotszky’s () developmental tradition, children first acquire connections between actions and outcomes in the world around them with the words spoken to them by their caregivers, and then internalize the same language system as a tool to regulate their own cognition and behavior. In adulthood, people continue to talk out loud and silently to themselves using inner speech, and such self-directed language production is assumed to continue to regulate many aspects of cognition and behavior (). For example, in memory, the phonological loop transfers to-be-remembered information into long-term memory through short-term rehearsal (???). The act of speaking out loud itself improves future retrieval, as shown by the production effect (???); and, the process of naming may guide category learning by drawing attention toward diagnostic features (Lupyan,). Verbal recoding can facilitate learning and recall of lengthy sequences by casting elements into chunks with recallable names (???). In the completion of everyday tasks, (???) argue that verbally coded instructions together with recurrent associative learning of real-world action sequences provide the control necessary for accomplishing routine tasks like making coffee or tea. Among these and other uses, a crowning achievement of language production is the ability to control the serial order of utterances to convey meaning in highly complex and flexible ways.
Verbal codes in speech
People are capable of overt and covert speech, which may be mediated by a common language production process. For example, according to the flexible abstraction hypothesis (), the selection of individual phonemes during covert or overt speech is controlled by a common process with relatively abstract phonemic codes. These abstract codes retain deep semantic and lexical features, but lack many of the articulatory features necessary for speaking out loud. As a result, inner speech may rely on these more abstract codes, which explains evidence that errors in overt speech can be driven more by lexical than phonemic similarity (). At the same time, these abstract codes can be used flexibly and further modified by articulatory processes that fill in necessary additional features to achieve overt speech. Although the flexible abstraction hypothesis is concerned mainly with speech overt and covert speech production, it is worth considering whether it extends to nonverbal language production such as typing. For example, the same abstract verbal codes mediating inner speech may be co-opted and further specified by motor processes controlling finger movements to achieve accurate and fluid keystroke production.
Verbal codes in sequence production
Sequence production more generally may also be mediated by verbal codes that trigger a plan-based mode of action control distinct from a more automatic stimulus-based mode of control (). For example, a stimulus-based mode of control refers to actions triggered in an automatic, reflex-like manner in response to well-learned cues from the environment. Whereas, a plan-based mode of control refers to goal-driven cognitive processes that set and supervise motor programs for complex sequencing of actions. Evidence for a distinction between control modes comes from the serial reaction time task (SRT, ???). The major finding from SRT tasks is that subjects learn to respond faster to targets that are presented in repeating or probabilistic sequences compared to random sequences, even if they are unable to explicitly describe the sequential regularities. At the same time, whether reaction times are sensitive to the frequency of particular targets or first-order transitions (e.g., repetitions or alternations) appears to depend on whether subjects possess explicit knowledge about sequential regularities in the task. For example, in a task where alternations were three times more likely than repetitions, subjects who were not aware of the manipulation showed faster responses to the more frequent alternations than repetitions, whereas subjects who were aware of the manipulation were equally fast for alternations and repetitions. One interpretation is that explicit knowledge of the transition probabilities allowed subjects to adopt a control-based mode, enabling action plans to mediate responses rather than more automatic frequency sensitive learning processes. Using a similar task, Tubau, Hommel, & López-Moliner (2007) further showed that subjects were more likely to adopt a plan-based mode (as evidenced by the elimination of the alternation benefit) when visual/verbal targets were used and when responses where followed by sounds, and plan-based control was disrupted when auditory noise was introduced. They suggested that use of phonemic codes in general may strongly influence subjects to adopt a plan-based vs. stimulus-based mode of action control.
References
Behmer, Lawrence P., and M. J. C. Crump. 2017. “Crunching Big Data with Finger Tips: How Typists Tune Their Performance Towards the Statistics of Natural Language.” In Big Data in Cognitive Science, edited by Michael N. Jones, 319–41. Routledge.
Crump, Matthew J. C., Walter Lai, and Nicholaus P. Brosowsky. n.d. “Instance Theory Predicts Information Theory: Episodic Uncertainty as a Determinant of Keystroke Dynamics.” Canadian Journal of Experimental Psychology NA: NA.
Crump, M. J. C., and Gordon D. Logan. 2010. “Hierarchical Control and Skilled Typing: Evidence for Word-Level Control over the Execution of Individual Keystrokes.” Journal of Experimental Psychology: Learning, Memory, and Cognition 36 (6): 1369–80. https://doi.org/10.1037/a0020696.
Fodor, Jerry A. 1983. The Modularity of Mind: An Essay on Faculty Psychology. Cambridge, Mass.: MIT Press.
Liu, Xianyun, M. J. C. Crump, and Gordon D. Logan. 2010. “Do You Know Where Your Fingers Have Been? Explicit Knowledge of the Spatial Layout of the Keyboard in Skilled Typists.” Memory & Cognition 38 (4): 474–84. https://doi.org/10.3758/MC.38.4.474.
Logan, Gordon D. 1988. “Toward an Instance Theory of Automatization.” Psychological Review 95 (4): 492–527. https://doi.org/10.1037/0033-295X.95.4.492.
———. 2018. “Automatic Control: How Experts Act Without Thinking.” Psychological Review 125 (4): 453–85. https://doi.org/10/gdtjfn.
Logan, Gordon D., and M. J. C. Crump. 2009. “The Left Hand Doesn’t Know What the Right Hand Is Doing: The Disruptive Effects of Attention to the Hands in Skilled Typewriting.” Psychological Science 20 (10): 1296–1300. https://doi.org/10.1111/j.1467-9280.2009.02442.x.
———. 2011. “Hierarchical Control of Cognitive Processes: The Case for Skilled Typewriting.” In Psychology of Learning and Motivation, edited by B. H. Ross, 54:1–27. Elsevier.
Massaro, Dominic W., and Peter A. Lucas. 1984. “Typing Letter Strings Varying in Orthographic Structure.” Acta Psychologica 57 (2): 109–31. https://doi.org/10.1016/0001-6918(84)90038-6.
Ostry, David J. 1983. “Determinants of Interkey Times in Typing.” In Cognitive Aspecdts of Skilled Typewriting, edited by William E. Cooper, 225–46. New York: Springer-Verlag.
Pinet, Svetlana, Johannes C. Ziegler, and F.-Xavier Alario. 2016. “Typing Is Writing: Linguistic Properties Modulate Typing Execution.” Psychonomic Bulletin & Review 23 (6): 1898–1906. https://doi.org/10.3758/s13423-016-1044-3.
Rumelhart, David E., and Donald A. Norman. 1982. “Simulating a Skilled Typist: A Study of Skilled Cognitive-Motor Performance.” Cognitive Science 6 (1): 1–36. https://doi.org/10.1207/s15516709cog0601_1.
Shaffer, L. H., and J. Hardwick. 1968. “Typing Performance as a Function of Text.” The Quarterly Journal of Experimental Psychology 20 (4): 360–69. https://doi.org/10.1080/14640746808400175.
Van Selst, M., and P. Jolicoeur. 1994. “A Solution to the Effect of Sample Size on Outlier Elimination.” The Quarterly Journal of Experimental Psychology 47A: 631–50. https://doi.org/10.1080/14640749408401131.
Will, Udo, Guido Nottbusch, and Rüdiger Weingarten. 2006. “Linguistic Units in Word Typing: Effects of Word Presentation Modes and Typing Delay.” Written Language & Literacy 9 (1): 153–76.