Analysis E2 Verbal Suppression
Matt
5/14/2019
E2_Analysis.RmdE2 IKSI Analysis
#load E2 data
E2_data <- talk_type_E2_data
# IKSI analysis
E2_data <- E2_data %>%
filter(letter_accuracy == 1,
iksis < 5000,
LetterType != "Space") %>%
mutate(subject = as.factor(subject),
suppression = as.factor(suppression),
LetterType = as.factor(LetterType)) %>%
group_by(subject,suppression,LetterType) %>%
summarise(mean_iksi = mean(modified_recursive_moving(iksis)$restricted),
prop_removed = modified_recursive_moving(iksis)$prop_removed)
E2_aov_out <- aov(mean_iksi ~ suppression*LetterType +
Error(subject/(suppression*LetterType)), E2_data)
knitr::kable(xtable(summary(E2_aov_out)))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 14 | 2869695.8 | 204978.27 | NA | NA |
| suppression | 5 | 1104110.3 | 220822.06 | 16.45400 | 0.0000000 |
| Residuals | 70 | 939439.9 | 13420.57 | NA | NA |
| LetterType | 1 | 3749036.6 | 3749036.64 | 21.27414 | 0.0004029 |
| Residuals | 14 | 2467151.0 | 176225.07 | NA | NA |
| suppression:LetterType | 5 | 949883.1 | 189976.62 | 13.96436 | 0.0000000 |
| Residuals | 70 | 952307.4 | 13604.39 | NA | NA |
First Letter one-way with linear contrasts
#load E1B data
E2_data <- talk_type_E2_data
# IKSI analysis
E2_data$suppression <- fct_relevel(E2_data$suppression,c("Normal","SayThe","TueThur","Alphabet","RandLetter","Count"))
E2_data <- E2_data %>%
filter(letter_accuracy == 1,
iksis < 5000,
LetterType != "Space") %>%
mutate(subject = as.factor(subject),
suppression = as.factor(suppression),
LetterType = as.factor(LetterType)) %>%
group_by(subject,suppression,LetterType) %>%
summarise(mean_iksi = mean(modified_recursive_moving(iksis)$restricted),
prop_removed = modified_recursive_moving(iksis)$prop_removed)
E2_FL_data <- E2_data %>%
filter(LetterType == "First")
E2_FL_aov_out <- aov(mean_iksi ~ suppression +
Error(subject/(suppression)), E2_FL_data)
knitr::kable(xtable(summary(E2_FL_aov_out)))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 14 | 5257407 | 375529.07 | NA | NA |
| suppression | 5 | 2049979 | 409995.82 | 15.29138 | 0 |
| Residuals | 70 | 1876855 | 26812.22 | NA | NA |
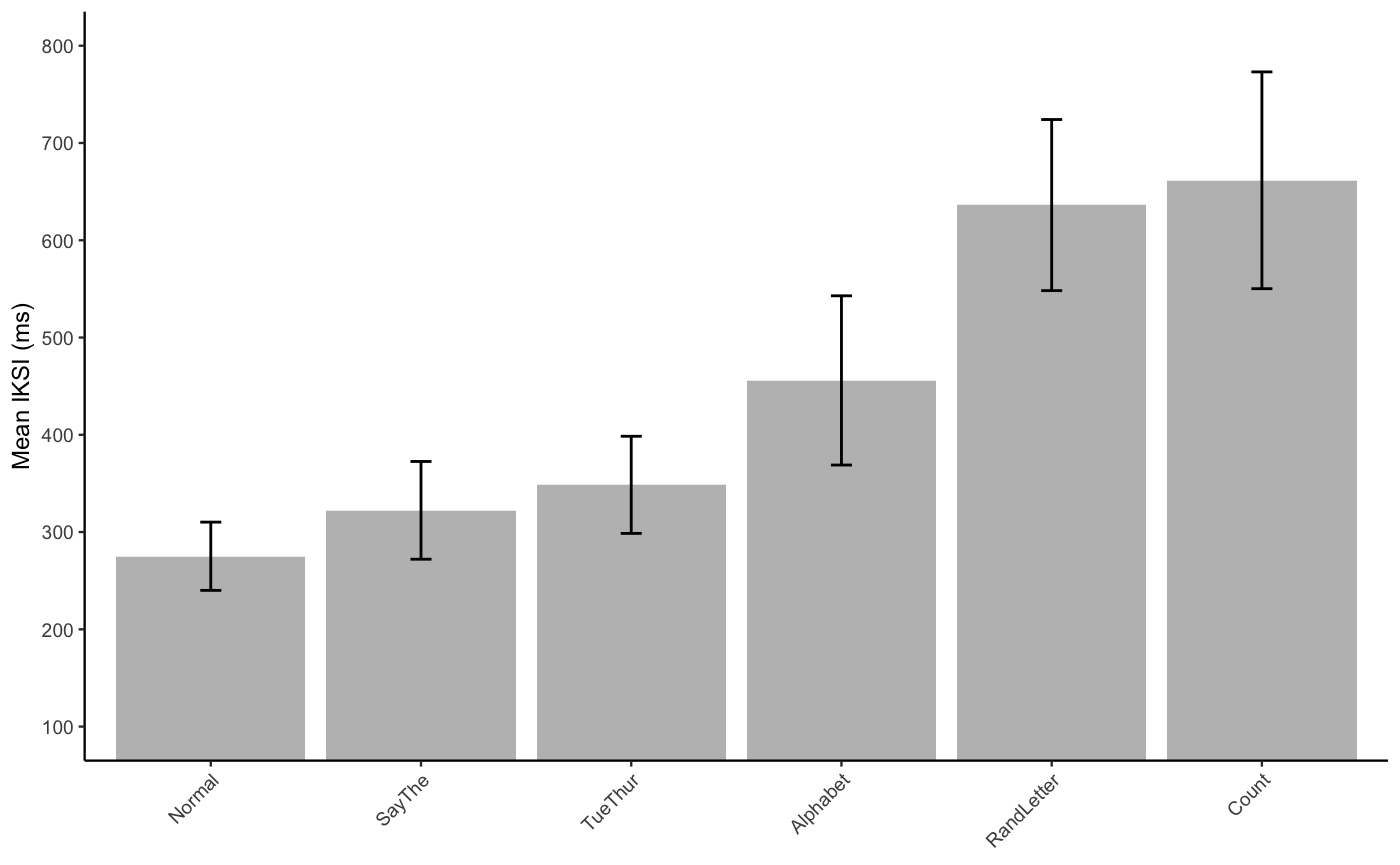
Plot
E2_FL_iksi_table <- E2_FL_data %>%
group_by(suppression) %>%
summarize(mIKSI = mean(mean_iksi),
sem = sd(mean_iksi)/sqrt(length(mean_iksi)))
E2_FL_graph_iksi <- ggplot(E2_FL_iksi_table, aes(x=suppression,
y=mIKSI))+
geom_bar(stat="identity", position="dodge", fill="grey")+
geom_errorbar(aes(ymin=mIKSI-sem,
ymax=mIKSI+sem), width=.1,
linetype="solid", position=position_dodge(.9))+
scale_fill_grey(start = 0.6, end = 0.8, na.value = "red",
aesthetics = "fill")+
theme_classic(base_size=9)+
theme(legend.position = "top",
legend.title = element_blank())+
coord_cartesian(ylim=c(100,800))+
scale_y_continuous(minor_breaks=seq(100,800,25),
breaks=seq(100,800,100))+
#scale_x_discrete(labels = c('Normal',
# 'Letter',
# 'Word',
# 'Letter',
# 'Word'))+
ylab("Mean IKSI (ms)")+
theme(axis.title.x = element_blank())+
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# facet_wrap(~suppression, scales = "free_x",
# strip.position="bottom")
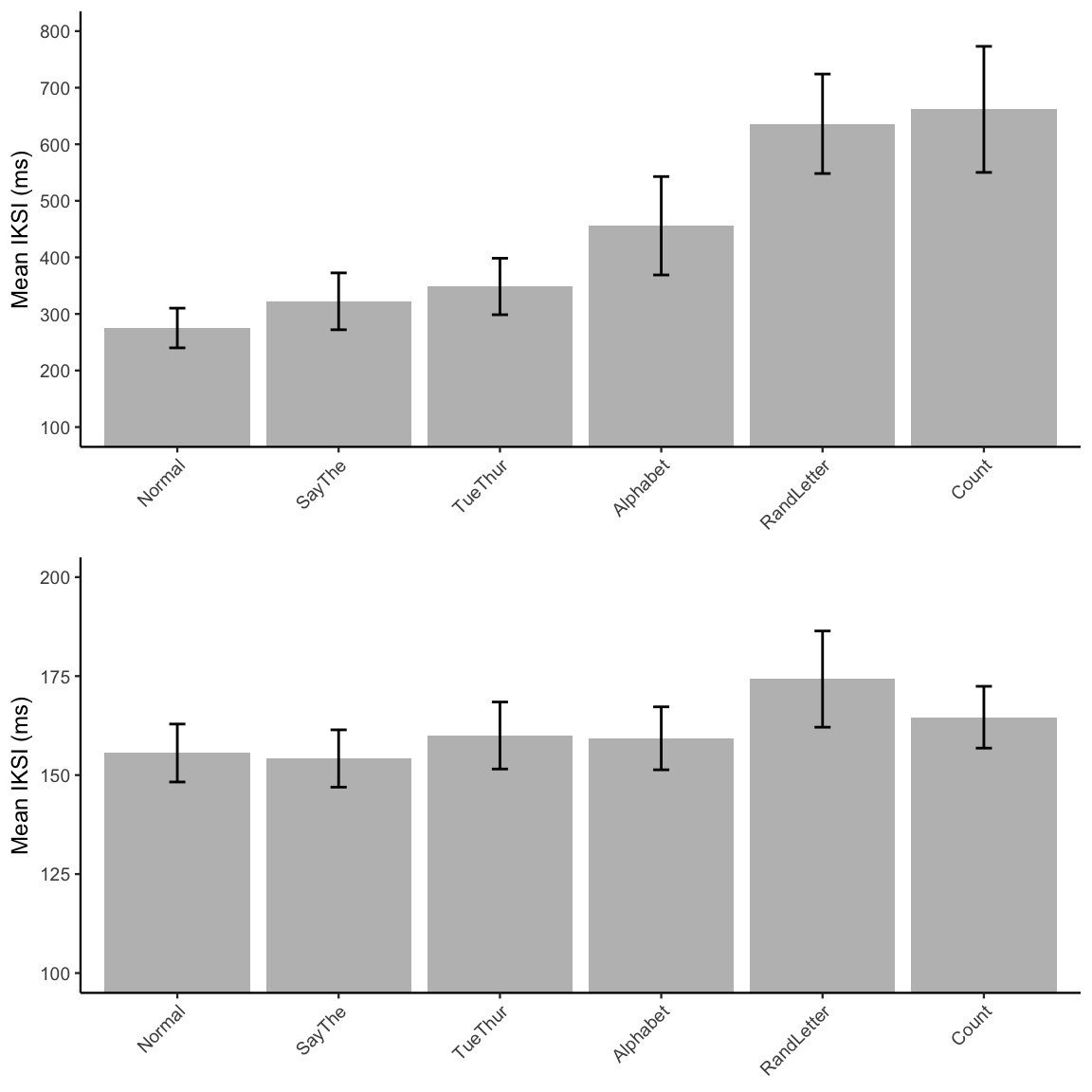
knitr::kable(E2_FL_iksi_table)| suppression | mIKSI | sem |
|---|---|---|
| Normal | 275.1379 | 35.08749 |
| SayThe | 322.3288 | 50.24586 |
| TueThur | 348.5493 | 49.93300 |
| Alphabet | 455.8985 | 86.99283 |
| RandLetter | 636.1838 | 87.95005 |
| Count | 661.6534 | 111.44788 |
contrasts
# Normal vs. All
E2_FL_NvsAll <- apa_print(t_contrast_rm(df=E2_FL_data,
subject = "subject",
dv = "mean_iksi",
condition = "suppression",
A_levels = c("Normal"),
B_levels = c("SayThe","TueThur","Alphabet","RandLetter","Count"),
contrast_weights = c(-1,1/5,1/5,1/5,1/5,1/5) ))##
## One Sample t-test
##
## data: contrast_vector
## t = 4.4699, df = 14, p-value = 0.0005288
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 109.1250 310.4447
## sample estimates:
## mean of x
## 209.7848# Normal vs. the and tuesday thursday
E2_FL_NvsTheThu <- apa_print(t_contrast_rm(df=E2_FL_data,
subject = "subject",
dv = "mean_iksi",
condition = "suppression",
A_levels = c("Normal"),
B_levels = c("SayThe","TueThur"),
contrast_weights = c(-1,1/2,1/2) ))##
## One Sample t-test
##
## data: contrast_vector
## t = 2.0697, df = 14, p-value = 0.05746
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -2.187929 122.790184
## sample estimates:
## mean of x
## 60.30113# the and tuesday thursday vs. alphabet
E2_FL_AlphavsTheThu <- apa_print(t_contrast_rm(df=E2_FL_data,
subject = "subject",
dv = "mean_iksi",
condition = "suppression",
A_levels = c("SayThe","TueThur"),
B_levels = c("Alphabet"),
contrast_weights = c(-1/2,-1/2,1) ))##
## One Sample t-test
##
## data: contrast_vector
## t = 2.6434, df = 14, p-value = 0.01928
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 22.71998 218.19895
## sample estimates:
## mean of x
## 120.4595E2_FL_AlphavsRandCnt <- apa_print(t_contrast_rm(df=E2_FL_data,
subject = "subject",
dv = "mean_iksi",
condition = "suppression",
A_levels = c("Alphabet"),
B_levels = c("RandLetter","Count"),
contrast_weights = c(-1,1/2,1/2) ))##
## One Sample t-test
##
## data: contrast_vector
## t = 3.5561, df = 14, p-value = 0.003163
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 76.60338 309.43679
## sample estimates:
## mean of x
## 193.0201Middle Letter one-way with linear contrasts
#load E1B data
E2_data <- talk_type_E2_data
# IKSI analysis
E2_data$suppression <- fct_relevel(E2_data$suppression,c("Normal","SayThe","TueThur","Alphabet","RandLetter","Count"))
E2_data <- E2_data %>%
filter(letter_accuracy == 1,
iksis < 5000,
LetterType != "Space") %>%
mutate(subject = as.factor(subject),
suppression = as.factor(suppression),
LetterType = as.factor(LetterType)) %>%
group_by(subject,suppression,LetterType) %>%
summarise(mean_iksi = mean(modified_recursive_moving(iksis)$restricted),
prop_removed = modified_recursive_moving(iksis)$prop_removed)
E2_ML_data <- E2_data %>%
filter(LetterType == "Middle")
E2_ML_aov_out <- aov(mean_iksi ~ suppression +
Error(subject/(suppression)), E2_ML_data)
knitr::kable(xtable(summary(E2_ML_aov_out)))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 14 | 79439.849 | 5674.2750 | NA | NA |
| suppression | 5 | 4014.308 | 802.8616 | 3.773794 | 0.0043972 |
| Residuals | 70 | 14892.258 | 212.7465 | NA | NA |
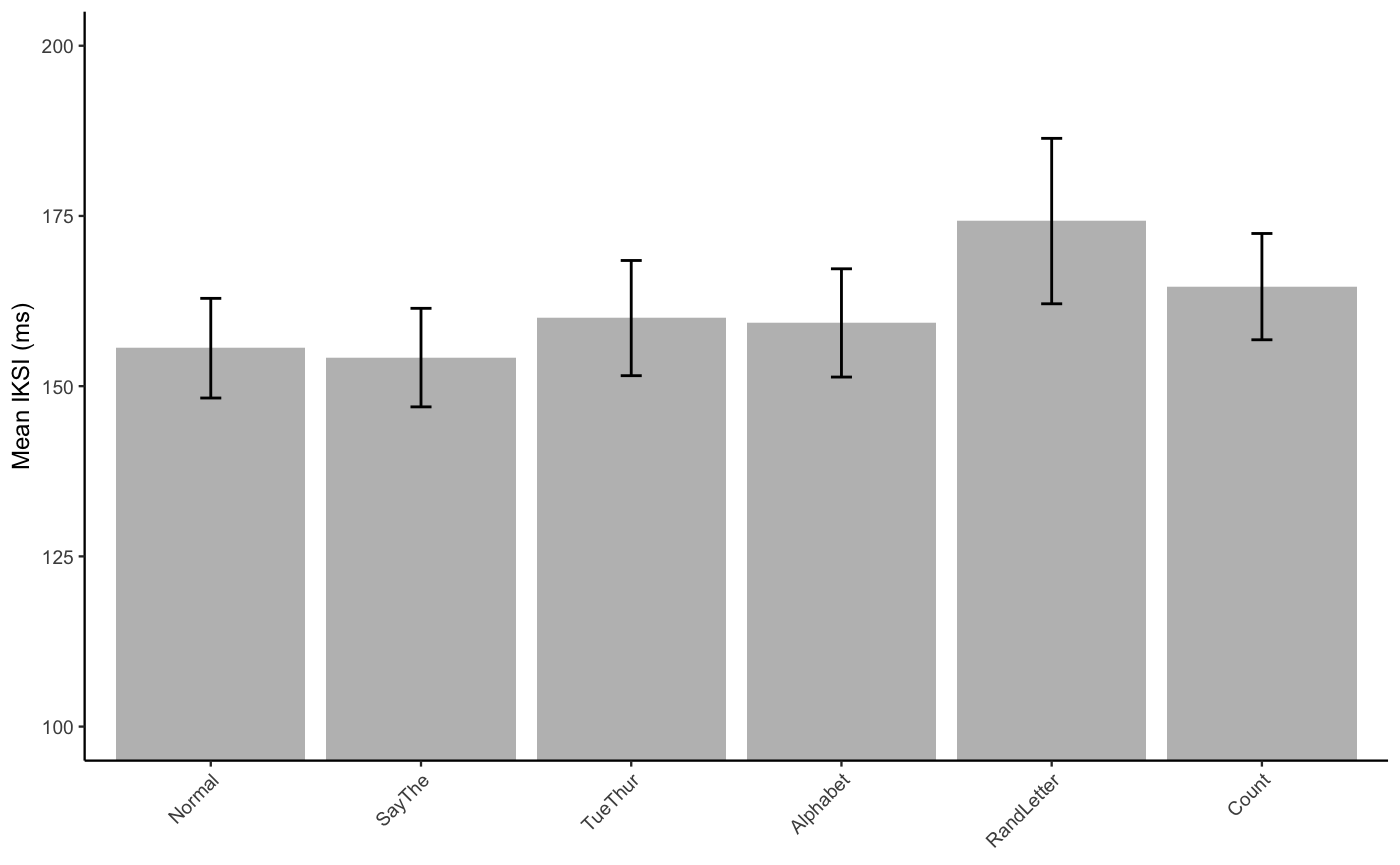
Plot
E2_ML_iksi_table <- E2_ML_data %>%
group_by(suppression) %>%
summarize(mIKSI = mean(mean_iksi),
sem = sd(mean_iksi)/sqrt(length(mean_iksi)))
E2_ML_graph_iksi <- ggplot(E2_ML_iksi_table, aes(x=suppression,
y=mIKSI))+
geom_bar(stat="identity", position="dodge", fill="grey")+
geom_errorbar(aes(ymin=mIKSI-sem,
ymax=mIKSI+sem), width=.1,
linetype="solid", position=position_dodge(.9))+
scale_fill_grey(start = 0.6, end = 0.8, na.value = "red",
aesthetics = "fill")+
theme_classic(base_size=9)+
theme(legend.position = "top",
legend.title = element_blank())+
coord_cartesian(ylim=c(100,200))+
scale_y_continuous(minor_breaks=seq(100,200,25),
breaks=seq(100,200,25))+
#scale_x_discrete(labels = c('Normal',
# 'Letter',
# 'Word',
# 'Letter',
# 'Word'))+
ylab("Mean IKSI (ms)")+
theme(axis.title.x = element_blank())+
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# facet_wrap(~suppression, scales = "free_x",
# strip.position="bottom")
knitr::kable(E2_ML_iksi_table)| suppression | mIKSI | sem |
|---|---|---|
| Normal | 155.5772 | 7.318144 |
| SayThe | 154.1945 | 7.236293 |
| TueThur | 159.9988 | 8.459759 |
| Alphabet | 159.2873 | 7.949713 |
| RandLetter | 174.2472 | 12.148583 |
| Count | 164.6184 | 7.805628 |
contrasts
# Normal vs. all but random
E2_ML_NvsAllbR <- apa_print(t_contrast_rm(df=E2_ML_data,
subject = "subject",
dv = "mean_iksi",
condition = "suppression",
A_levels = c("Normal"),
B_levels = c("SayThe","TueThur","Alphabet","Count"),
contrast_weights = c(-1,1/4,1/4,1/4,1/4) ))##
## One Sample t-test
##
## data: contrast_vector
## t = 1.8359, df = 14, p-value = 0.08771
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -0.6642766 8.5593328
## sample estimates:
## mean of x
## 3.947528# Rand vs. Normal
E2_ML_RandvsNormal <- apa_print(t_contrast_rm(df=E2_ML_data,
subject = "subject",
dv = "mean_iksi",
condition = "suppression",
A_levels = c("Normal"),
B_levels = c("RandLetter"),
contrast_weights = c(-1,1) ))##
## One Sample t-test
##
## data: contrast_vector
## t = 2.7359, df = 14, p-value = 0.01608
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 4.033847 33.306027
## sample estimates:
## mean of x
## 18.66994First Letter Accuracy one-way with linear contrasts
#load E1B data
E2_data <- talk_type_E2_data
# IKSI analysis
E2_data$suppression <- fct_relevel(E2_data$suppression,c("Normal","SayThe","TueThur","Alphabet","RandLetter","Count"))
E2_data <- E2_data %>%
filter(LetterType != "Space") %>%
mutate(subject = as.factor(subject),
suppression = as.factor(suppression),
LetterType = as.factor(LetterType)) %>%
group_by(subject,suppression,LetterType) %>%
summarise(mean_acc = mean(letter_accuracy))
E2acc_FL_data <- E2_data %>%
filter(LetterType == "First")
E2acc_FL_aov_out <- aov(mean_acc ~ suppression +
Error(subject/(suppression)), E2acc_FL_data)
knitr::kable(xtable(summary(E2acc_FL_aov_out)))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 14 | 0.1360795 | 0.0097200 | NA | NA |
| suppression | 5 | 0.0256047 | 0.0051209 | 3.001159 | 0.0163903 |
| Residuals | 70 | 0.1194424 | 0.0017063 | NA | NA |
E2acc_FL_apa_print <- apa_print(E2acc_FL_aov_out)
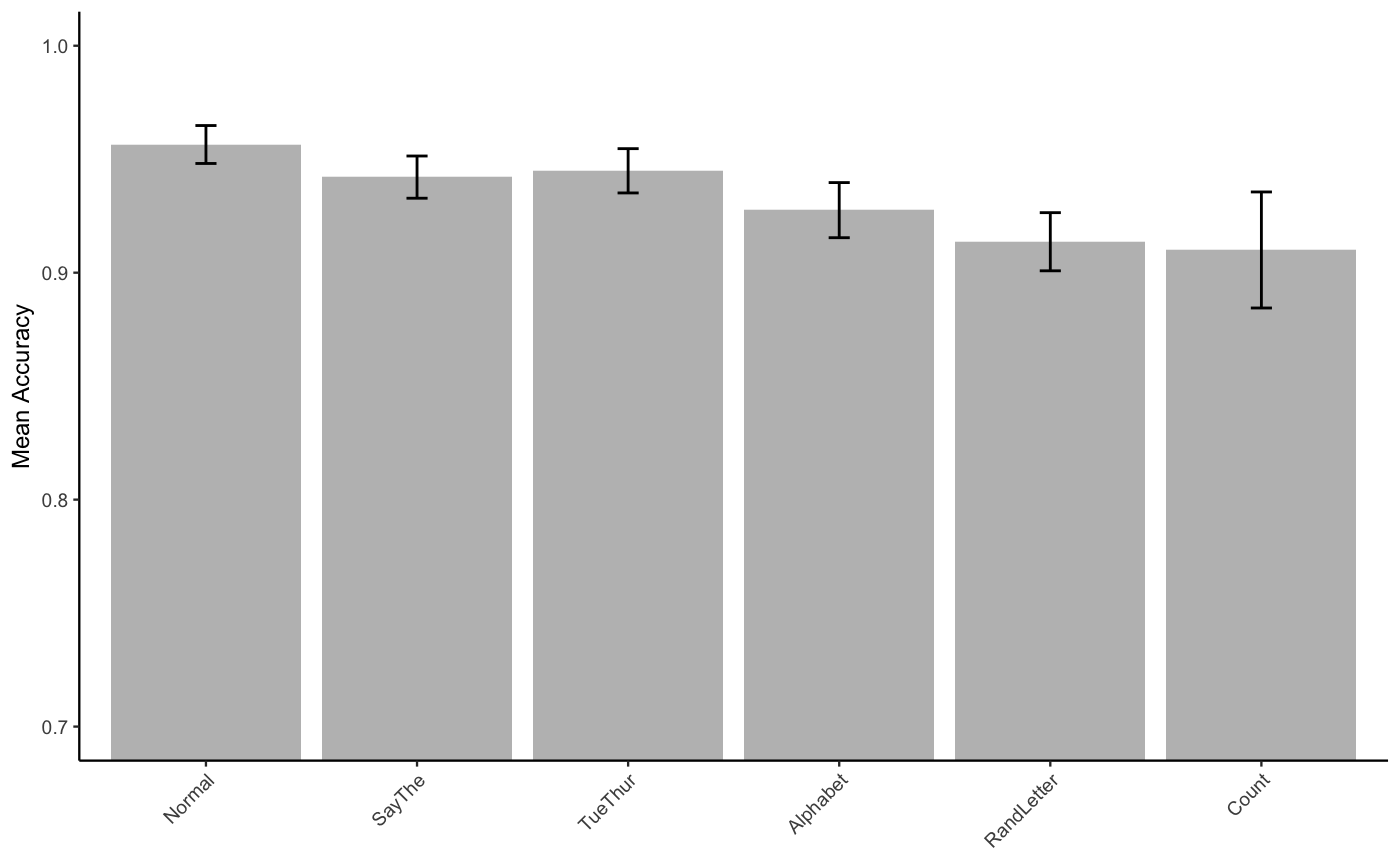
E2acc_FL_means <- model.tables(E2acc_FL_aov_out,"means")Plot
E2acc_FL_table <- E2acc_FL_data %>%
group_by(suppression) %>%
summarize(mAcc = mean(mean_acc),
sem = sd(mean_acc)/sqrt(length(mean_acc)))
E2acc_FL_graph_acc <- ggplot(E2acc_FL_table, aes(x=suppression,
y=mAcc))+
geom_bar(stat="identity", position="dodge", fill="grey")+
geom_errorbar(aes(ymin=mAcc-sem,
ymax=mAcc+sem), width=.1,
linetype="solid", position=position_dodge(.9))+
scale_fill_grey(start = 0.6, end = 0.8, na.value = "red",
aesthetics = "fill")+
theme_classic(base_size=9)+
theme(legend.position = "top",
legend.title = element_blank())+
coord_cartesian(ylim=c(0.7,1))+
scale_y_continuous(minor_breaks=seq(0.7,1,.1),
breaks=seq(0.7,1,.1))+
#scale_x_discrete(labels = c('Normal',
# 'Letter',
# 'Word',
# 'Letter',
# 'Word'))+
ylab("Mean Accuracy")+
theme(axis.title.x = element_blank())+
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# facet_wrap(~suppression, scales = "free_x",
# strip.position="bottom")
knitr::kable(E2acc_FL_table)| suppression | mAcc | sem |
|---|---|---|
| Normal | 0.9564783 | 0.0083601 |
| SayThe | 0.9421110 | 0.0093006 |
| TueThur | 0.9448931 | 0.0097569 |
| Alphabet | 0.9275567 | 0.0121435 |
| RandLetter | 0.9136387 | 0.0128113 |
| Count | 0.9100080 | 0.0255653 |
contrasts
# Normal vs. the tue/thur
E2acc_FL_NvsTheThur <- apa_print(t_contrast_rm(df=E2acc_FL_data,
subject = "subject",
dv = "mean_acc",
condition = "suppression",
A_levels = c("Normal"),
B_levels = c("SayThe","TueThur"),
contrast_weights = c(-1,1/2,1/2) ))##
## One Sample t-test
##
## data: contrast_vector
## t = -1.7432, df = 14, p-value = 0.1032
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -0.028941753 0.002989327
## sample estimates:
## mean of x
## -0.01297621# Normal the tue/thur vs alpha rand count
E2acc_FL_NTheThvsARC <- apa_print(t_contrast_rm(df=E2acc_FL_data,
subject = "subject",
dv = "mean_acc",
condition = "suppression",
A_levels = c("Normal","SayThe","TueThur"),
B_levels = c("Alphabet","RandLetter","Count"),
contrast_weights = c(-1/3,-1/3,-1/3,1/3,1/3,1/3) ))##
## One Sample t-test
##
## data: contrast_vector
## t = -3.0697, df = 14, p-value = 0.008319
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -0.052251532 -0.009267813
## sample estimates:
## mean of x
## -0.03075967Middle Letter Accuracy one-way with linear contrasts
#load E1B data
E2_data <- talk_type_E2_data
# IKSI analysis
E2_data$suppression <- fct_relevel(E2_data$suppression,c("Normal","SayThe","TueThur","Alphabet","RandLetter","Count"))
E2_data <- E2_data %>%
filter(LetterType != "Space") %>%
mutate(subject = as.factor(subject),
suppression = as.factor(suppression),
LetterType = as.factor(LetterType)) %>%
group_by(subject,suppression,LetterType) %>%
summarise(mean_acc = mean(letter_accuracy))
E2acc_ML_data <- E2_data %>%
filter(LetterType == "Middle")
E2acc_ML_aov_out <- aov(mean_acc ~ suppression +
Error(subject/(suppression)), E2acc_ML_data)
knitr::kable(xtable(summary(E2acc_ML_aov_out)))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 14 | 0.2990676 | 0.0213620 | NA | NA |
| suppression | 5 | 0.0801541 | 0.0160308 | 5.596677 | 0.0002145 |
| Residuals | 70 | 0.2005042 | 0.0028643 | NA | NA |
E2acc_ML_apa_print <- apa_print(E2acc_ML_aov_out)
E2acc_ML_means <- model.tables(E2acc_ML_aov_out,"means")Plot
E2acc_ML_table <- E2acc_ML_data %>%
group_by(suppression) %>%
summarize(mAcc = mean(mean_acc),
sem = sd(mean_acc)/sqrt(length(mean_acc)))
E2acc_ML_graph_acc <- ggplot(E2acc_ML_table, aes(x=suppression,
y=mAcc))+
geom_bar(stat="identity", position="dodge", fill="grey")+
geom_errorbar(aes(ymin=mAcc-sem,
ymax=mAcc+sem), width=.1,
linetype="solid", position=position_dodge(.9))+
scale_fill_grey(start = 0.6, end = 0.8, na.value = "red",
aesthetics = "fill")+
theme_classic(base_size=9)+
theme(legend.position = "top",
legend.title = element_blank())+
coord_cartesian(ylim=c(0.7,1))+
scale_y_continuous(minor_breaks=seq(0.7,1,.1),
breaks=seq(0.7,1,.1))+
#scale_x_discrete(labels = c('Normal',
# 'Letter',
# 'Word',
# 'Letter',
# 'Word'))+
ylab("Mean Accuracy")+
theme(axis.title.x = element_blank()) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# facet_wrap(~suppression, scales = "free_x",
# strip.position="bottom")
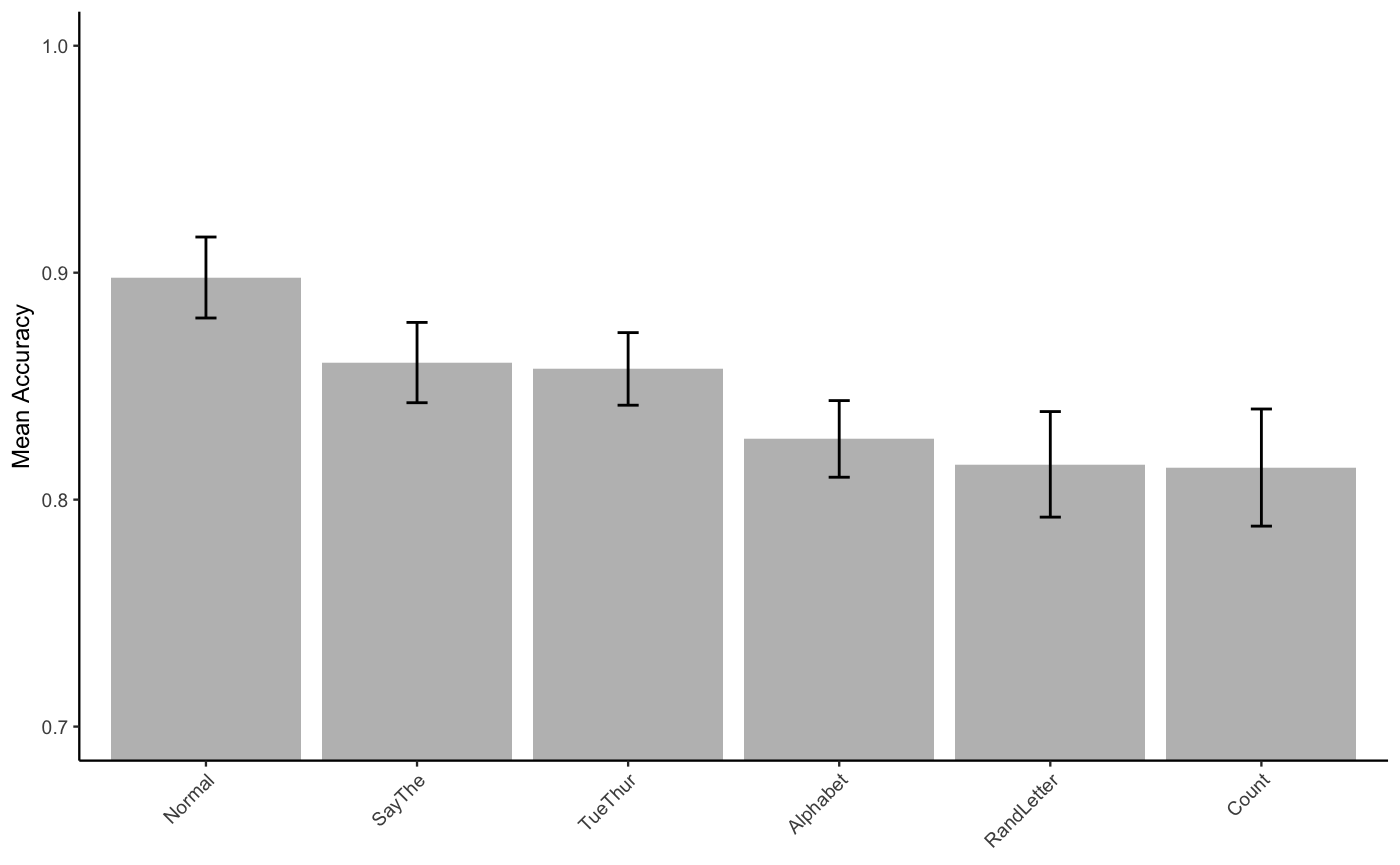
knitr::kable(E2acc_ML_table)| suppression | mAcc | sem |
|---|---|---|
| Normal | 0.8978740 | 0.0178426 |
| SayThe | 0.8603967 | 0.0176930 |
| TueThur | 0.8576019 | 0.0159934 |
| Alphabet | 0.8267572 | 0.0168839 |
| RandLetter | 0.8155491 | 0.0232558 |
| Count | 0.8141323 | 0.0258036 |
contrasts
# Normal vs. the tue/thur
E2acc_ML_NvsTheThur <- apa_print(t_contrast_rm(df=E2acc_ML_data,
subject = "subject",
dv = "mean_acc",
condition = "suppression",
A_levels = c("Normal"),
B_levels = c("SayThe","TueThur"),
contrast_weights = c(-1,1/2,1/2) ))##
## One Sample t-test
##
## data: contrast_vector
## t = -1.9116, df = 14, p-value = 0.07662
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -0.082492462 0.004743188
## sample estimates:
## mean of x
## -0.03887464# Normal the tue/thur vs alpha rand count
E2acc_ML_NTheThvsARC <- apa_print(t_contrast_rm(df=E2acc_ML_data,
subject = "subject",
dv = "mean_acc",
condition = "suppression",
A_levels = c("Normal","SayThe","TueThur"),
B_levels = c("Alphabet","RandLetter","Count"),
contrast_weights = c(-1/3,-1/3,-1/3,1/3,1/3,1/3) ))##
## One Sample t-test
##
## data: contrast_vector
## t = -4.2358, df = 14, p-value = 0.0008306
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -0.08005405 -0.02623533
## sample estimates:
## mean of x
## -0.05314469speed accuracy tradeoff
library(ggrepel)
E2_iksi_both <- rbind(E2_FL_iksi_table,
E2_ML_iksi_table)
E2_iksi_both <- cbind(E2_iksi_both,
Letter_Position = rep(c("First","Middle"), each=6))
E2_acc_both <- rbind(E2acc_FL_table,
E2acc_ML_table)
E2_acc_both <- cbind(E2_acc_both,
Letter_Position = rep(c("First","Middle"), each=6))
E2_SA <- cbind(E2_iksi_both, accuracy = E2_acc_both$mAcc)
E2_SA_graph <- ggplot(E2_SA, aes(x=mIKSI, y=accuracy,
shape=Letter_Position,
color=Letter_Position,
label=suppression))+
geom_point()+
geom_text_repel(size=1.7, color="black")+
coord_cartesian(xlim=c(100,700), ylim=c(.8,1))+
scale_x_continuous(breaks=seq(100,700,100))+
scale_color_grey(start = 0.2, end = 0.5, na.value = "red",
aesthetics = "color", guide =FALSE)+
theme_classic(base_size=10)+
ylab("Mean Accuracy")+
xlab("Mean IKSI (ms)")+
#facet_wrap(~Letter_Position, nrow=2,
# strip.position="right")+
theme(legend.position ="top",
legend.direction = "horizontal")+
guides(shape = guide_legend(label.hjust = 0,
keywidth=0.1))+
labs(shape="Letter")
E2_SA_graph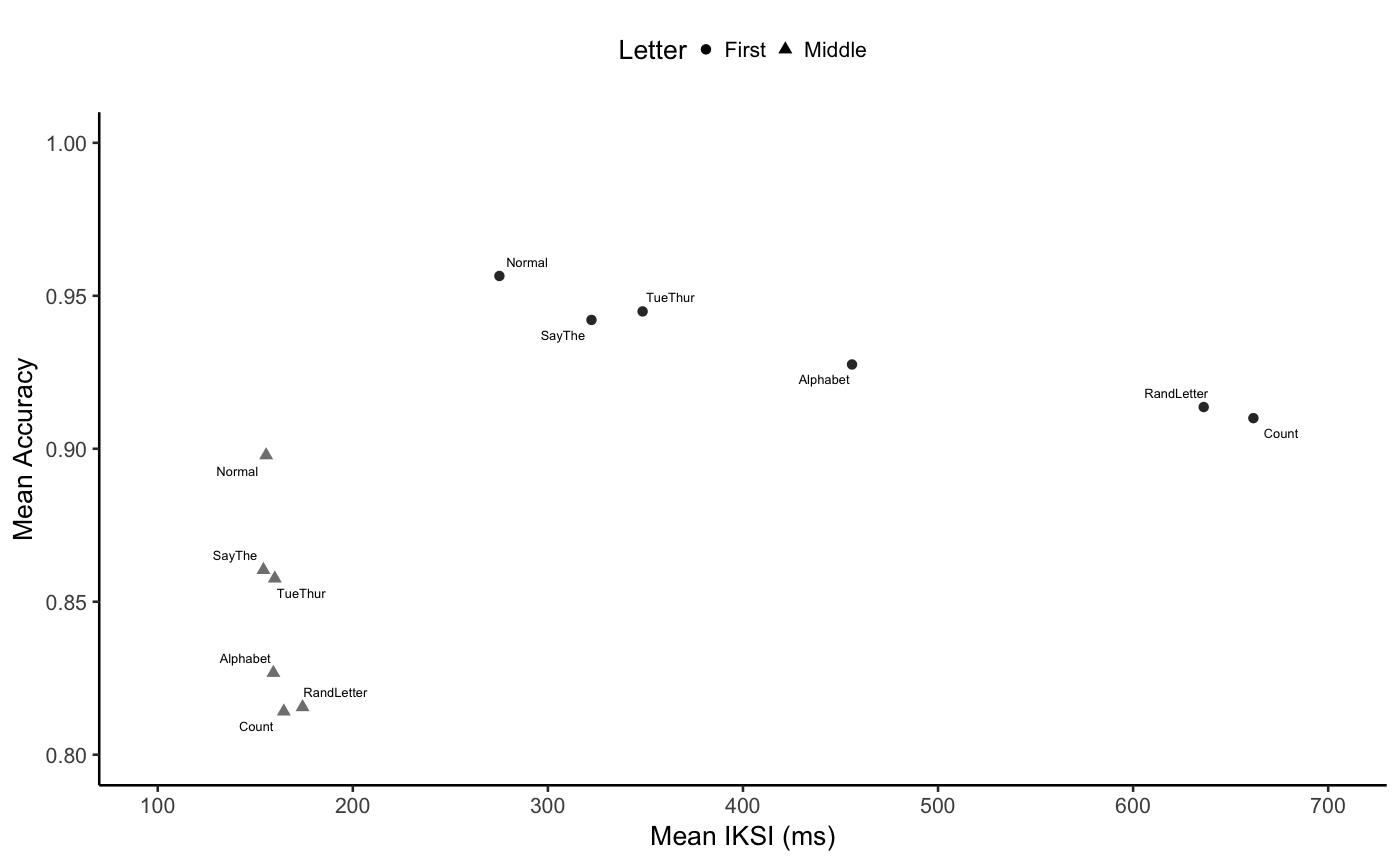
#load E2 data
E2_data <- talk_type_E2_data
# IKSI analysis
E2_data <- E2_data %>%
filter(accuracy == 1,
iksis < 5000,
LetterType != "Space") %>%
mutate(subject = as.factor(subject),
suppression = as.factor(suppression),
LetterType = as.factor(LetterType)) %>%
group_by(subject,suppression,LetterType) %>%
summarise(mean_iksi = mean(modified_recursive_moving(iksis)$restricted),
prop_removed = modified_recursive_moving(iksis)$prop_removed)
E2_data$suppression <- fct_relevel(E2_data$suppression,c("Normal","SayThe","TueThur","Alphabet","RandLetter","Count"))
E2_iksi_table <- E2_data %>%
group_by(suppression,LetterType) %>%
summarize(mIKSI = mean(mean_iksi),
sem = sd(mean_iksi)/sqrt(length(mean_iksi)))
#levels(E1A_iksi_table$paragraph) <- c("Say Letter", "Say Word")
E2_graph_iksi <- ggplot(E2_iksi_table, aes(x=LetterType,
y=mIKSI,
fill=LetterType))+
geom_bar(stat="identity",position="dodge")+
geom_errorbar(aes(ymin=mIKSI-sem,
ymax=mIKSI+sem), width=.1,
linetype="solid")+
scale_fill_grey(start = 0.6, end = 0.8, na.value = "red",
aesthetics = "fill")+
theme_classic(base_size=12)+
theme(legend.position = "none",
legend.title = element_blank())+
ylab("Mean IKSI (ms)")+
xlab("Letter position")+
facet_wrap(~suppression, nrow=1)
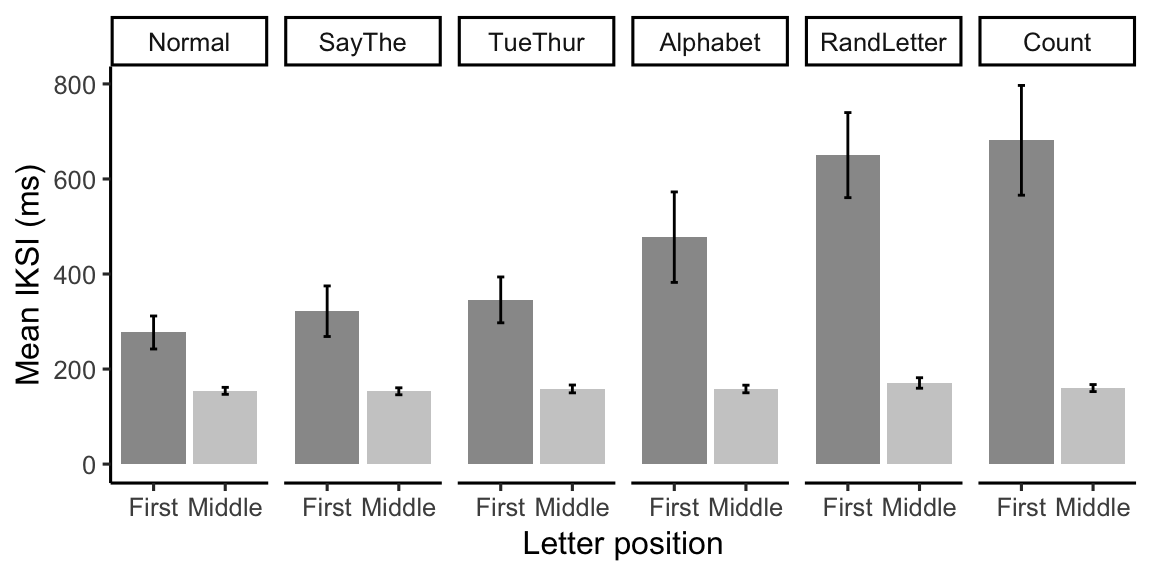
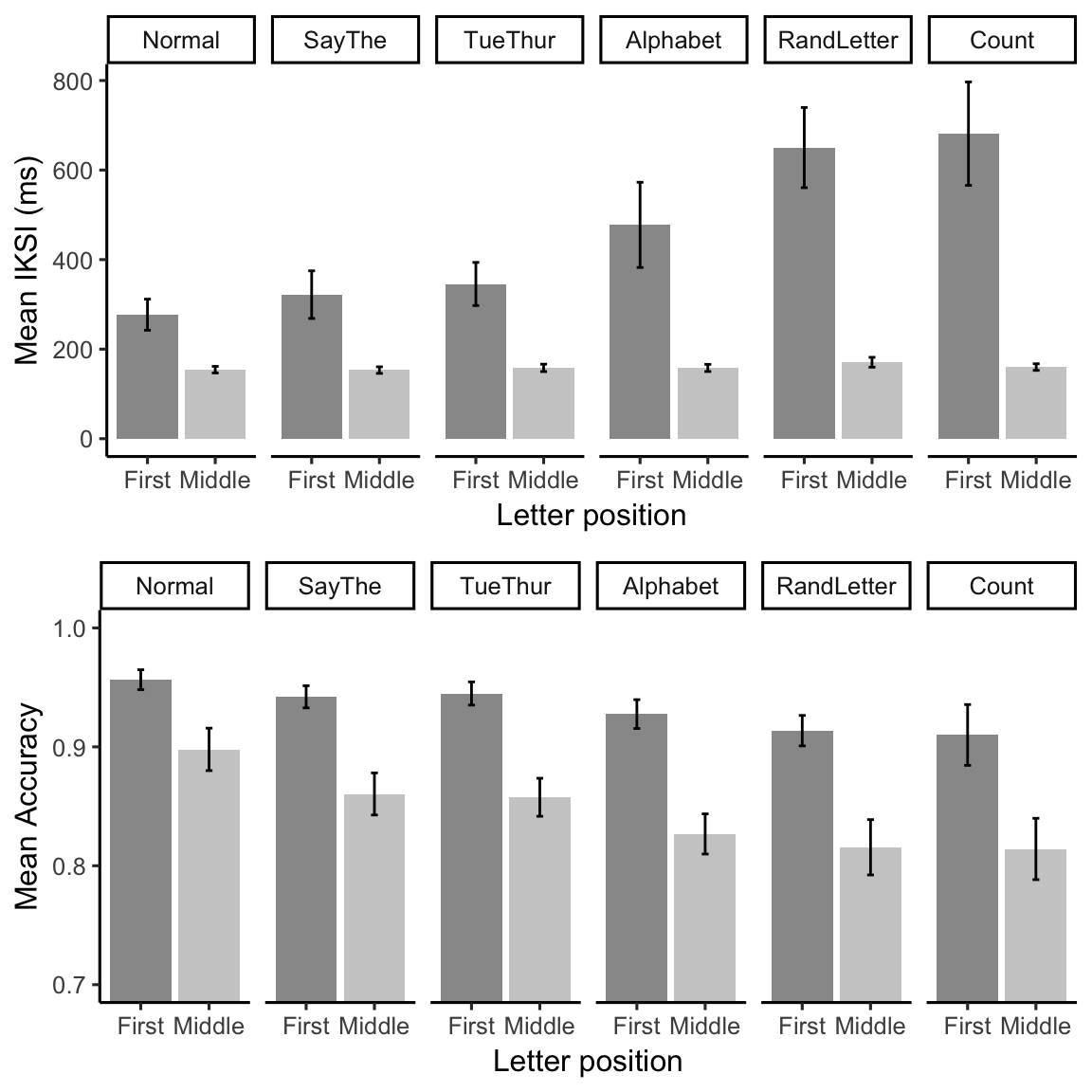
knitr::kable(E2_iksi_table)| suppression | LetterType | mIKSI | sem |
|---|---|---|---|
| Normal | First | 276.9624 | 34.722182 |
| Normal | Middle | 154.1825 | 7.340545 |
| SayThe | First | 321.7087 | 53.218289 |
| SayThe | Middle | 153.2280 | 7.335822 |
| TueThur | First | 345.5774 | 48.242259 |
| TueThur | Middle | 158.1935 | 8.228906 |
| Alphabet | First | 477.5381 | 95.189790 |
| Alphabet | Middle | 158.0736 | 7.993724 |
| RandLetter | First | 650.1842 | 89.511870 |
| RandLetter | Middle | 170.7278 | 11.030549 |
| Count | First | 681.3246 | 115.473813 |
| Count | Middle | 159.9962 | 7.404675 |
get letter level accuracy estimates
This chunk was previously evaluated, and the talk_type_e2_data.RData file was updated with estimates of letter level accuracy.
E2acc_data <- talk_type_E2_data
E2acc_data$closest[is.na(E2acc_data$closest)] <- ""
letter_accuracy <- E2acc_data$accuracy
for(i in 1:dim(E2acc_data)[1]){
clet <- as.character(E2acc_data[i,]$letters)
cword <- unlist(strsplit(as.character(E2acc_data[i,]$closest),split=""))
if(E2acc_data$accuracy[i] == 0){
if(length(cword)>0){
if(E2acc_data[i,]$LetterPosition <= length(cword)){
if(clet != " "){
if(clet == cword[E2acc_data[i,]$LetterPosition]){
letter_accuracy[i] <- 1
} else {
letter_accuracy[i] <- 0
}
}
}
}
}
}
E2acc_data <- cbind(E2acc_data,letter_accuracy)Accuracy ANOVA
E2acc_data <- talk_type_E2_data
# Accuracy
E2acc_data <- E2acc_data %>%
mutate(subject = as.factor(subject),
suppression = as.factor(suppression),
LetterType = as.factor(LetterType)) %>%
filter(LetterType != "Space") %>%
group_by(subject,suppression, LetterType) %>%
summarise(mean_acc = mean(letter_accuracy))
E2acc_aov_out <- aov(mean_acc ~ suppression*LetterType + Error(subject/(suppression*LetterType)), E2acc_data)
E2acc_apa_print <- apa_print(E2acc_aov_out)
E2acc_means <- model.tables(E2acc_aov_out,"means")
knitr::kable(xtable(summary(E2acc_aov_out)))| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| Residuals | 14 | 0.3972025 | 0.0283716 | NA | NA |
| suppression | 5 | 0.0965600 | 0.0193120 | 4.961481 | 0.0006037 |
| Residuals | 70 | 0.2724671 | 0.0038924 | NA | NA |
| LetterType | 1 | 0.3410941 | 0.3410941 | 125.849925 | 0.0000000 |
| Residuals | 14 | 0.0379445 | 0.0027103 | NA | NA |
| suppression:LetterType | 5 | 0.0091988 | 0.0018398 | 2.712384 | 0.0268243 |
| Residuals | 70 | 0.0474795 | 0.0006783 | NA | NA |
Accuracy table and plots
E2acc_data$suppression <- fct_relevel(E2acc_data$suppression,c("Normal","SayThe","TueThur","Alphabet","RandLetter","Count"))
E2_acc_table <- E2acc_data %>%
group_by(suppression,LetterType) %>%
summarize(mAcc = mean(mean_acc),
sem = sd(mean_acc)/sqrt(length(mean_acc)))
#levels(E1A_acc_table$paragraph) <- c("Say Letter", "Say Word")
E2_graph_acc <- ggplot(E2_acc_table, aes(x=LetterType,
y=mAcc,
fill=LetterType))+
geom_bar(stat="identity",position="dodge")+
geom_errorbar(aes(ymin=mAcc-sem,
ymax=mAcc+sem), width=.1,
linetype="solid")+
scale_fill_grey(start = 0.6, end = 0.8, na.value = "red",
aesthetics = "fill")+
theme_classic(base_size=12)+
theme(legend.position = "none",
legend.title = element_blank())+
ylab("Mean Accuracy")+
xlab("Letter position")+
coord_cartesian(ylim=c(.7,1))+
facet_wrap(~suppression, nrow=1)
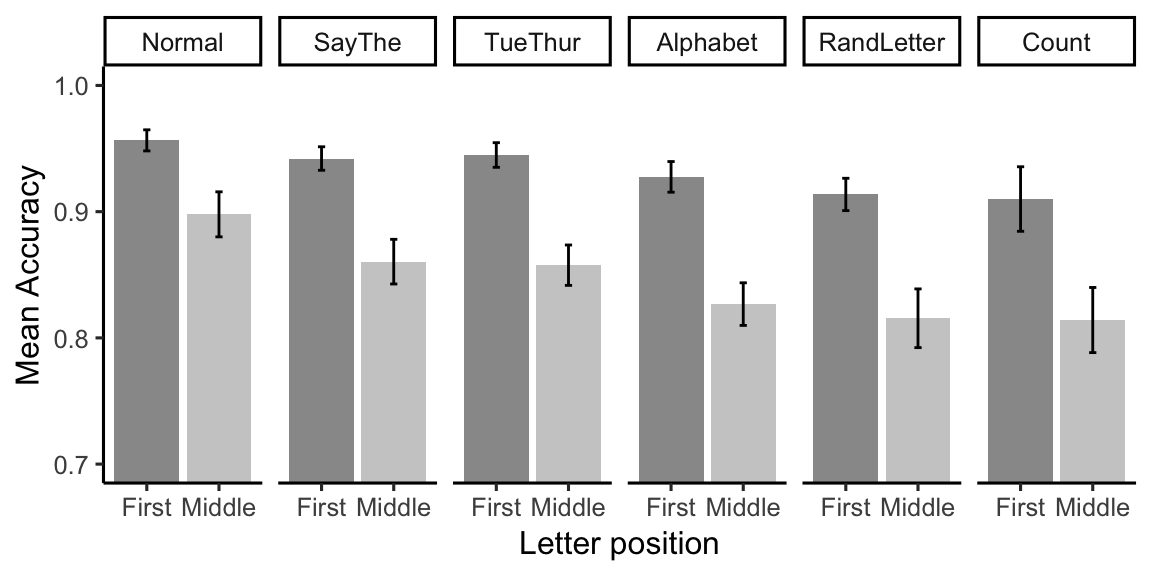
knitr::kable(E2_acc_table)| suppression | LetterType | mAcc | sem |
|---|---|---|---|
| Normal | First | 0.9564783 | 0.0083601 |
| Normal | Middle | 0.8978740 | 0.0178426 |
| SayThe | First | 0.9421110 | 0.0093006 |
| SayThe | Middle | 0.8603967 | 0.0176930 |
| TueThur | First | 0.9448931 | 0.0097569 |
| TueThur | Middle | 0.8576019 | 0.0159934 |
| Alphabet | First | 0.9275567 | 0.0121435 |
| Alphabet | Middle | 0.8267572 | 0.0168839 |
| RandLetter | First | 0.9136387 | 0.0128113 |
| RandLetter | Middle | 0.8155491 | 0.0232558 |
| Count | First | 0.9100080 | 0.0255653 |
| Count | Middle | 0.8141323 | 0.0258036 |
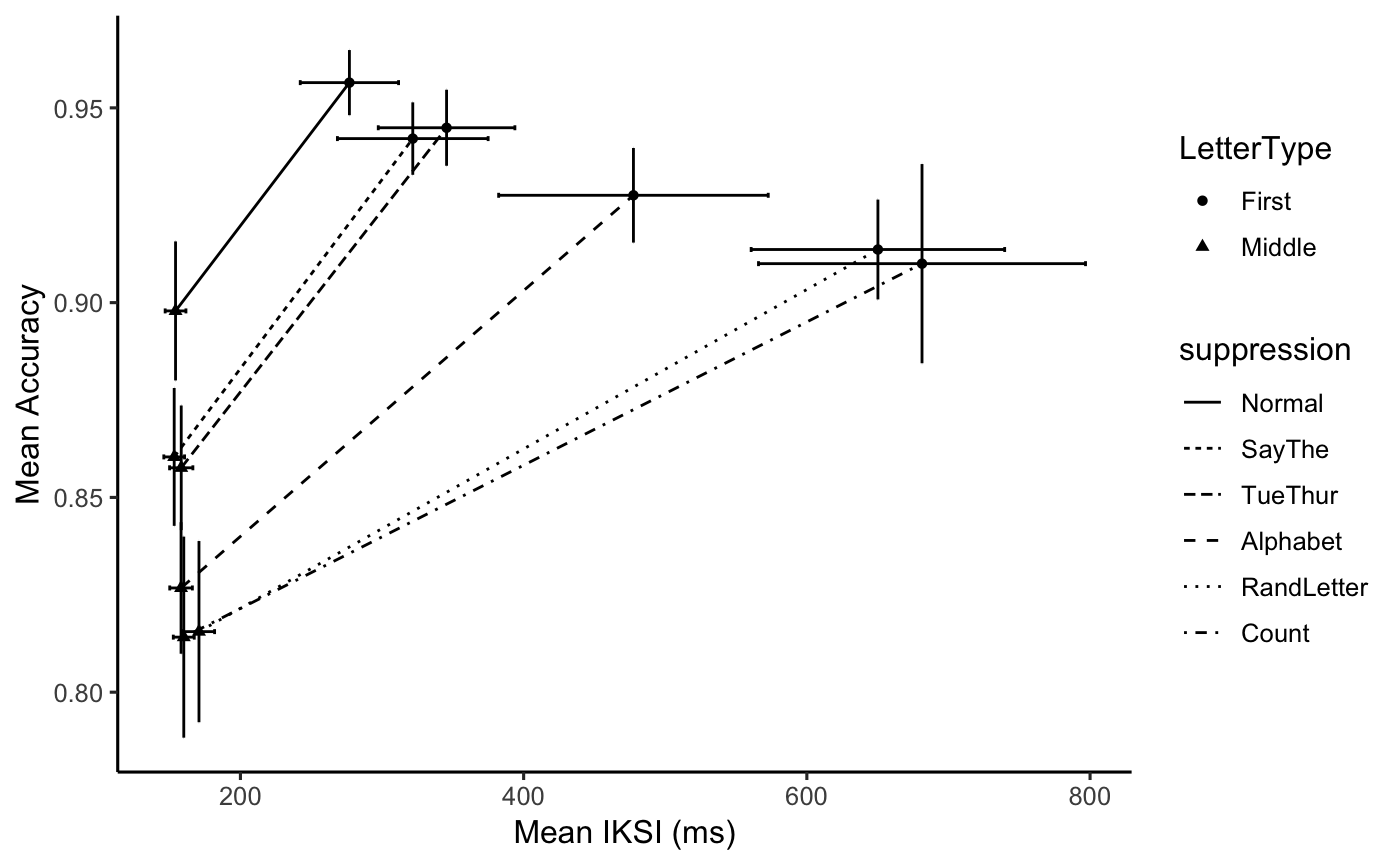
Speed accuracy tradeoff
tradeoff <- E2_iksi_table
tradeoff <- cbind(tradeoff,accuracy = E2_acc_table$mAcc,
accuracy_sem = E2_acc_table$sem)
ggplot(tradeoff, aes(x=mIKSI, y=accuracy,
group = suppression,
shape= LetterType,
linetype = suppression))+
geom_point()+
geom_line() +
geom_errorbar(aes(ymin=accuracy-accuracy_sem,
ymax=accuracy+accuracy_sem), width=.1,
linetype="solid")+
geom_errorbarh(aes(xmin=mIKSI-sem,
xmax=mIKSI+sem), width=.2,
linetype="solid")+
theme_classic(base_size=12)+
xlab("Mean IKSI (ms)")+
ylab("Mean Accuracy")