Show the code
library(tidyverse)
library(openai)
library(patchwork)
library(xtable)Matthew J. C. Crump 
Started. Finished.
The previous simulations focused on the Stroop and Flanker tasks. This simulation uses a version of the Simon task.
In a Simon task, participants respond to stimulus using a right or left manual response. For example, a red circle could require the right response, and a green circle a left response. The stimuli are presented in one of two locations on a screen: to the left or right of center. In this case, the spatial location of the stimulus can interfere with the assigned response to identify the stimulus. For example, people are faster to press the right key to identify the red stimulus when it is presented in the right location compared to the left location on the screen.
library(tidyverse)
library(openai)
library(patchwork)
library(xtable)Notes: 20 simulated subjects. 20 Simon trials each. 50/50 congruent and incongruent trials.
The prompt contains only basic information to complete the task.
Used gpt-3.5-turbo-16k, with max tokens 10000.
Problems: Still getting the occasional invalid JSON back, mostly due to the chatbot prefacing its response with a message before the JSON. This thread may be helpful https://community.openai.com/t/getting-response-data-as-a-fixed-consistent-json-response/28471/31?page=2.
# Use letters H and F
simon_items <- data.frame(stimulus = c("red","red","green","green"),
instruction = "Identify stimulus. Respond right for red. Respond left for green.",
location = c("left","right","left","right"),
response = "?",
reaction_time = "?")
#set up variables to store data
all_sim_data <- tibble()
gpt_response_list <- list()
# request multiple subjects
# submit a query to open ai using the following prompt
# note: responses in JSON format are requested
for(i in 1:20){
print(i)
# construct trials data frame
simon_trials <- simon_items[rep(1:nrow(simon_items),5),]
trials <- simon_trials
trials <- trials[sample(1:nrow(trials)),]
trials <- trials %>%
mutate(trial = 1:nrow(trials)) %>%
relocate(instruction) %>%
relocate(trial)
# run the api call to openai
gpt_response <- create_chat_completion(
model = "gpt-3.5-turbo-16k",
max_tokens = 10000,
messages = list(
list(
"role" = "system",
"content" = "You are a simulated participant in a human cognition experiment. Complete the task as instructed and record your simulated responses in a JSON file. Do not include any explanations, only provide a RFC8259 compliant JSON response."),
list("role" = "assistant",
"content" = "OK, I am ready."),
list("role" = "user",
"content" = paste('You are a simulated participant in a human cognition experiment. Complete the task as instructed and record your simulated responses in JSON. Your task is to simulate human performance in a letter identification task. You will be given the task in the form a JSON object. The JSON object contains the task instruction and the stimulus on each trial. Your task is to follow the instruction and respond to the stimulus as quickly and accurately as a human participant would. The instructions are to identify the stimulus by responding right for red, and responding left for green. When you simulate data make sure it conforms to how humans would perform this task. The JSON object contains the symbol ? in locations where you will generate simulated responses. You will generate a simulated identification response, and a simulated reaction time for each trial. Put the simulated identification response and reaction time into a JSON array using this format: [{"trial": "trial number, integer", "instruction" = "the task instruction, string", "stimulus": "the stimulus, string", "location": "the location of the stimulus, string", "response": "the simulated identification response, string","reaction_time": "the simulated reaction time, milliseconds an integer"}].', "\n\n", jsonlite::toJSON(trials), collapse = "\n")
)
)
)
# save the output from openai
gpt_response_list[[i]] <- gpt_response
print(gpt_response$usage$total_tokens)
# validate the JSON
test_JSON <- jsonlite::validate(gpt_response$choices$message.content)
print(test_JSON)
# validation checks pass, write the simulated data to all_sim_data
if(test_JSON == TRUE){
sim_data <- jsonlite::fromJSON(gpt_response$choices$message.content)
if(sum(names(sim_data) == c("trial","instruction","stimulus","location","response","reaction_time")) == 6) {
sim_data <- sim_data %>%
mutate(sim_subject = i)
all_sim_data <- rbind(all_sim_data,sim_data)
}
}
}
# model responses are in JSON format
save.image("data/simulation_10.RData")load(file = "data/simulation_10.RData")The LLM occasionally returns invalid JSON. The simulation ran 20 times.
total_subjects <- length(unique(all_sim_data$sim_subject))There were 19 out of 20 valid simulated subjects.
The model made too many mistakes to analyse RTs.
all_sim_data <- all_sim_data %>%
mutate(reaction_time = as.numeric(reaction_time))
# get mean RTs in each condition for each subject
rt_data_subject_compatible <- all_sim_data %>%
mutate(compatible = case_when(stimulus == "red" && location == "right" ~ "compatible",
stimulus == "red" && location == "left" ~ "incompatible",
stimulus == "green" && location == "right" ~ "incompatible",
stimulus == "green" && location == "left" ~ "compatible")
)%>%
mutate(accuracy = case_when(stimulus == "red" && response == "right" ~ TRUE,
stimulus == "red" && response != "right" ~ FALSE,
stimulus == "green" && response == "left" ~ TRUE,
stimulus == "green" && response != "left" ~ FALSE
)
) %>%
filter(accuracy == TRUE) %>%
group_by(compatible,sim_subject) %>%
summarize(mean_rt = mean(reaction_time), .groups = "drop")
# Compute difference scores for each subject
rt_data_subject_simon <- rt_data_subject_compatible %>%
pivot_wider(names_from = compatible,
values_from = mean_rt) %>%
mutate(Simon_effect = incompatible-compatible)
# make plots
F1A <- ggplot(rt_data_subject_compatible, aes(x = compatible,
y = mean_rt))+
geom_violin()+
stat_summary(fun = "mean",
geom = "crossbar",
color = "red")+
geom_point()+
theme_classic(base_size=15)+
ylab("Mean Simulated Reaction Time") +
ggtitle("A")
F1B <- ggplot(rt_data_subject_simon, aes(x = ' ',
y = Simon_effect))+
geom_violin()+
stat_summary(fun = "mean",
geom = "crossbar",
color = "red")+
geom_point()+
theme_classic(base_size=15)+
ylab("Simulated Simon Effects")+
xlab("Incompatible - Compatible")+
ggtitle("B")
F1A + F1BHere is a histogram of the individual simulated reaction times.
ggplot(all_sim_data, aes(x=reaction_time))+
geom_histogram(binwidth=50, color="white")+
theme_classic()+
xlab("Simulated Reaction Times")
The prompt did not specify to produce values with different endings. As with previous simulations, the model prefers values ending in 0.
all_sim_data <- all_sim_data %>%
mutate(ending_digit = stringr::str_extract(all_sim_data$reaction_time, "\\d$")) %>%
mutate(ending_digit = as.numeric(ending_digit))
ggplot(all_sim_data, aes(x=ending_digit))+
geom_histogram(binwidth=1, color="white")+
scale_x_continuous(breaks=seq(0,9,1))+
theme_classic(base_size = 10)+
xlab("Simulated RT Ones Digit")
# report accuracy data
accuracy_data_subject <- all_sim_data %>%
mutate(compatible = case_when(stimulus == "red" & location == "right" ~ "compatible",
stimulus == "red" & location == "left" ~ "incompatible",
stimulus == "green" & location == "right" ~ "incompatible",
stimulus == "green" & location == "left" ~ "compatible")
)%>%
mutate(accuracy = case_when(stimulus == "red" & response == "right" ~ TRUE,
stimulus == "red" & response != "right" ~ FALSE,
stimulus == "green" & response == "left" ~ TRUE,
stimulus == "green" & response != "left" ~ FALSE
)
) %>%
group_by(compatible,sim_subject) %>%
summarize(proportion_correct = mean(accuracy), .groups = "drop")
ggplot(accuracy_data_subject, aes(x = compatible,
y = proportion_correct))+
geom_violin()+
stat_summary(fun = "mean",
geom = "crossbar",
color = "red")+
geom_point()+
theme_classic(base_size=15)+
ylab("Simulated Proportion Correct")+
xlab("Compatibility")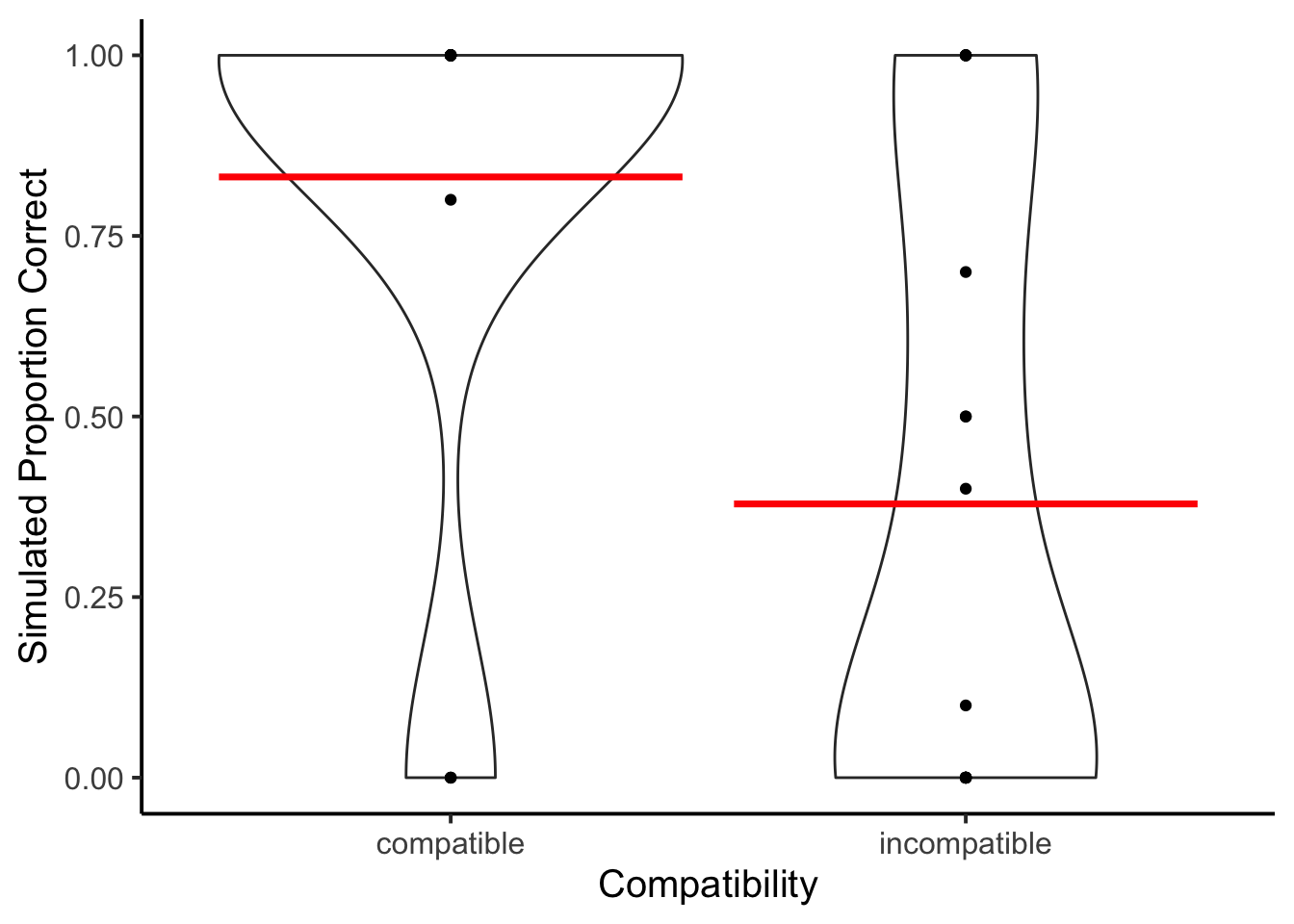
There was a clear Simon effect in the accuracy data. There were several simulated subjects who had no correct trials in one of the two conditions, so reaction time data wasn’t analyzed further.
The model in some sense fell prey to the Simon effect, as it performed terribly on incompatible trials. On the one hand it had no problem issuing responses, but the data did not resemble typical ranges of reaction times in this task. Perhaps the GPT simulation would improve with variations on the prompt structure.