Show the code
library(tidyverse)
library(openai)
library(patchwork)
library(xtable)Matthew J. C. Crump 
Started. Finished.
Simulation 3 attempted to model the list-wide proportion congruent effect. The code frequently returned invalid JSON.
This simulation used the approach from simulation 5, which appears to allow longer prompts that return valid JSON with higher frequency.
library(tidyverse)
library(openai)
library(patchwork)
library(xtable)Notes: 30 simulated subjects. 48 Stroop trials each. Odd numbered subjects are given high proportion congruent list, even numbered are given low proportion congruent list.
Started at 1:26pm finished at 1:56pm
Total tokens per prompt ranged from 3500 to 4200+.
Unlike the previous simulations, each subject is given a different randomized order.
Used gpt-3.5-turbo-16k, with max tokens 10000.
Problems: This code produced 28 valid JSON files out of 30. Much better than last time. And, the prompt had a typo (that I have left in the code).
## typo
"instruction" = "the task instruction, string" "word": "the name of the word
## added comma
"instruction" = "the task instruction, string", "word": "the name of the wordThe two invalid returns were cases where the model was being chatty, and rather than only returning JSON, it also included a preface, like, “Here is my response…”. And, I haven’t written error checking code to find possible JSON inside a text response. It’s possible the two invalid cases actually have valid JSON in the text response. The data should be in gpt_response_list.
# use the colors red, green, blue, and yellow
# four possible congruent items
congruent_items <- data.frame(word = c("red","green","blue","yellow"),
color = c("red","green","blue","yellow"))
# 12 possible congruent items
incongruent_items <- data.frame(word = c("red","red","red",
"green","green","green",
"blue","blue","blue",
"yellow","yellow","yellow"),
color = c("green","blue","yellow",
"blue","yellow","red",
"red","yellow","green",
"red","blue","green"))
#set up variables to store data
all_sim_data <- tibble()
gpt_response_list <- list()
# request multiple subjects
# submit a query to open ai using the following prompt
# note: responses in JSON format are requested
for(i in 1:30){
print(i)
# construct trials data frame
if (i %% 2 == 1) {
proportion_congruent <- "high"
congruent_trials <- congruent_items[rep(1:nrow(congruent_items),3*3),]
incongruent_trials <- incongruent_items[rep(1:nrow(incongruent_items),1),]
} else {
proportion_congruent <- "low"
congruent_trials <- congruent_items[rep(1:nrow(congruent_items),3),]
incongruent_trials <- incongruent_items[rep(1:nrow(incongruent_items),3),]
}
trials <- rbind(congruent_trials,incongruent_trials)
trials <- trials[sample(1:nrow(trials)),]
trials <- trials %>%
mutate(trial = 1:nrow(trials),
"instruction" = "Identify color",
response = "?",
reaction_time = "?") %>%
relocate(instruction) %>%
relocate(trial)
# run the api call to openai
gpt_response <- create_chat_completion(
model = "gpt-3.5-turbo-16k",
max_tokens = 10000,
messages = list(
list(
"role" = "system",
"content" = "You are a simulated participant in a human cognition experiment. Complete the task as instructed and record your simulated responses in a JSON file"),
list("role" = "assistant",
"content" = "OK, I am ready."),
list("role" = "user",
"content" = paste('You are a simulated participant in a human cognition experiment. Complete the task as instructed and record your simulated responses in a JSON file. Your task is to simulate human performance in Stroop task. You will be shown a Stroop task in the form a JSON object. The JSON object contains the word and color presented on each trial. Your task is to identify the ink-color of the word as quickly and accurately as a human participant would. The JSON object contains the symbol ? in locations where you will generate simulated responses. You will generate a simulated identification response, and a simulated reaction time. Put the simulated identification response and reaction time into a JSON array using this format: [{"trial": "trial number, integer", "instruction" = "the task instruction, string" "word": "the name of the word, string","color": "the color of the word, string","response": "the simulated identification response, string","reaction_time": "the simulated reaction time, milliseconds an integer"}].',
"\n\n",
jsonlite::toJSON(trials), collapse = "\n")
)
)
)
# save the output from openai
gpt_response_list[[i]] <- gpt_response
print(gpt_response$usage$total_tokens)
# validate the JSON
test_JSON <- jsonlite::validate(gpt_response$choices$message.content)
print(test_JSON)
# validation checks pass, write the simulated data to all_sim_data
if(test_JSON == TRUE){
sim_data <- jsonlite::fromJSON(gpt_response$choices$message.content)
if(sum(names(sim_data) == c("trial","instruction","word","color","response","reaction_time")) == 6) {
sim_data <- sim_data %>%
mutate(sim_subject = i,
proportion_congruent = proportion_congruent)
all_sim_data <- rbind(all_sim_data,sim_data)
}
}
}
# model responses are in JSON format
save.image("data/simulation_6.RData")load(file = "data/simulation_6.RData")The LLM occasionally returns invalid JSON. The simulation ran 20 times.
total_subjects <- length(unique(all_sim_data$sim_subject))There were 26 out of 30 valid simulated subjects. Two of the simulations returned invalid JSON, and two of them returned JSON with the wrong headers for the data frame.
# get mean RTs in each condition for each subject
rt_data_subject_congruency <- all_sim_data %>%
mutate(congruency = case_when(word == color ~ "congruent",
word != color ~ "incongruent")) %>%
mutate(accuracy = case_when(response == color ~ TRUE,
response != color ~ FALSE)) %>%
filter(accuracy == TRUE) %>%
group_by(proportion_congruent,congruency,sim_subject) %>%
summarize(mean_rt = mean(reaction_time), .groups = "drop")
# make plots
ggplot(rt_data_subject_congruency, aes(x = congruency,
y = mean_rt))+
geom_violin()+
stat_summary(fun = "mean",
geom = "crossbar",
color = "red")+
geom_point()+
theme_classic(base_size=15)+
ylab("Mean Simulated Reaction Time") +
facet_wrap(~proportion_congruent)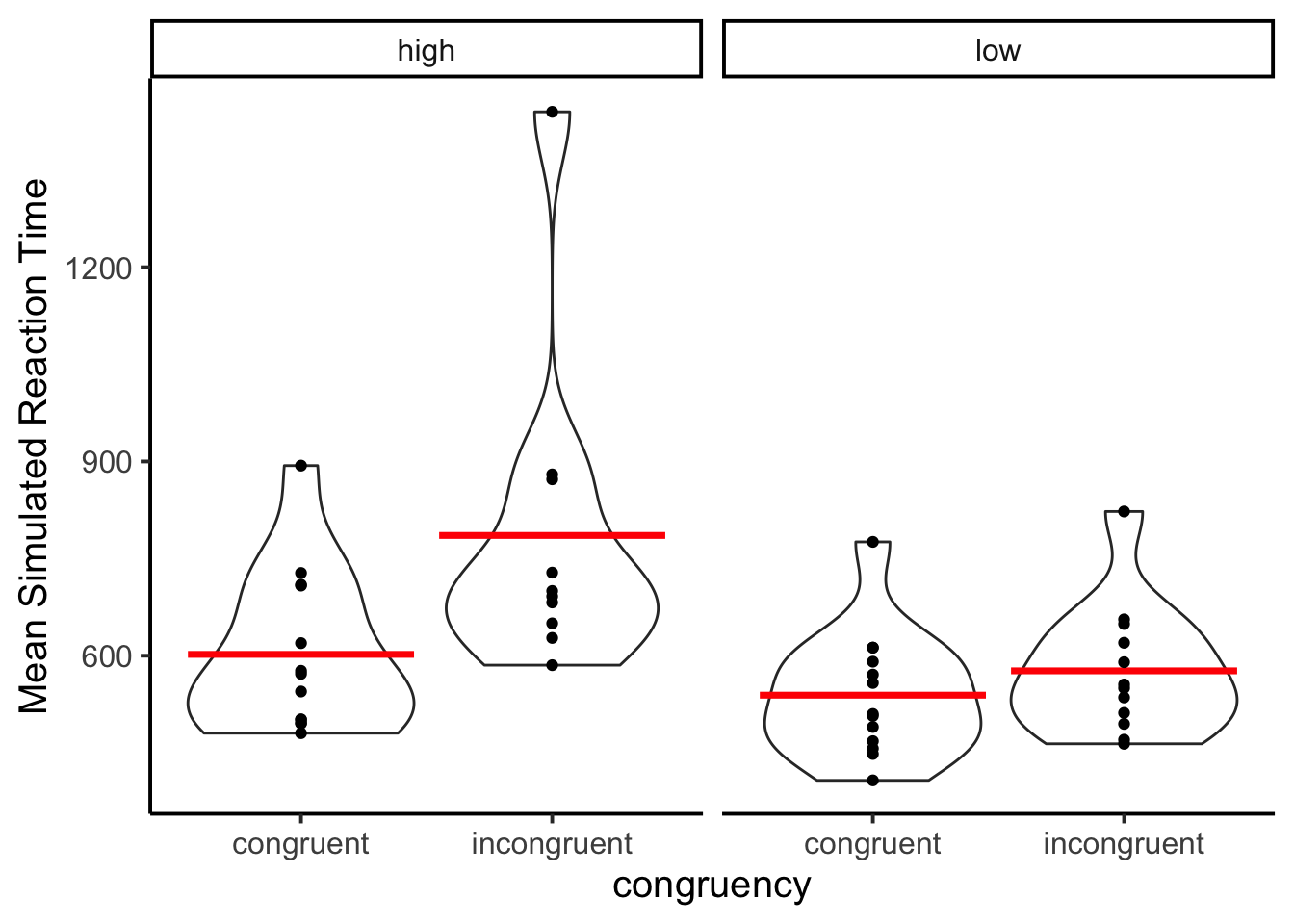
The figure shows a larger mean Stroop effect for the simulated subjects in the high proportion than low proportion congruent conditions.
As with previous simulations, the reaction times look sort of Ex-Gaussian, and this time there appears to be some large outliers.
ggplot(all_sim_data, aes(x=reaction_time))+
geom_histogram(binwidth=50, color="white")+
theme_classic()+
xlab("Simulated Reaction Times")
The prompt did not specify to produce values with different endings. As with previous simulations, the model seems to prefer values ending in 0.
all_sim_data <- all_sim_data %>%
mutate(ending_digit = stringr::str_extract(all_sim_data$reaction_time, "\\d$")) %>%
mutate(ending_digit = as.numeric(ending_digit))
ggplot(all_sim_data, aes(x=ending_digit))+
geom_histogram(binwidth=1, color="white")+
scale_x_continuous(breaks=seq(0,9,1))+
theme_classic(base_size = 10)+
xlab("Simulated RT Ones Digit")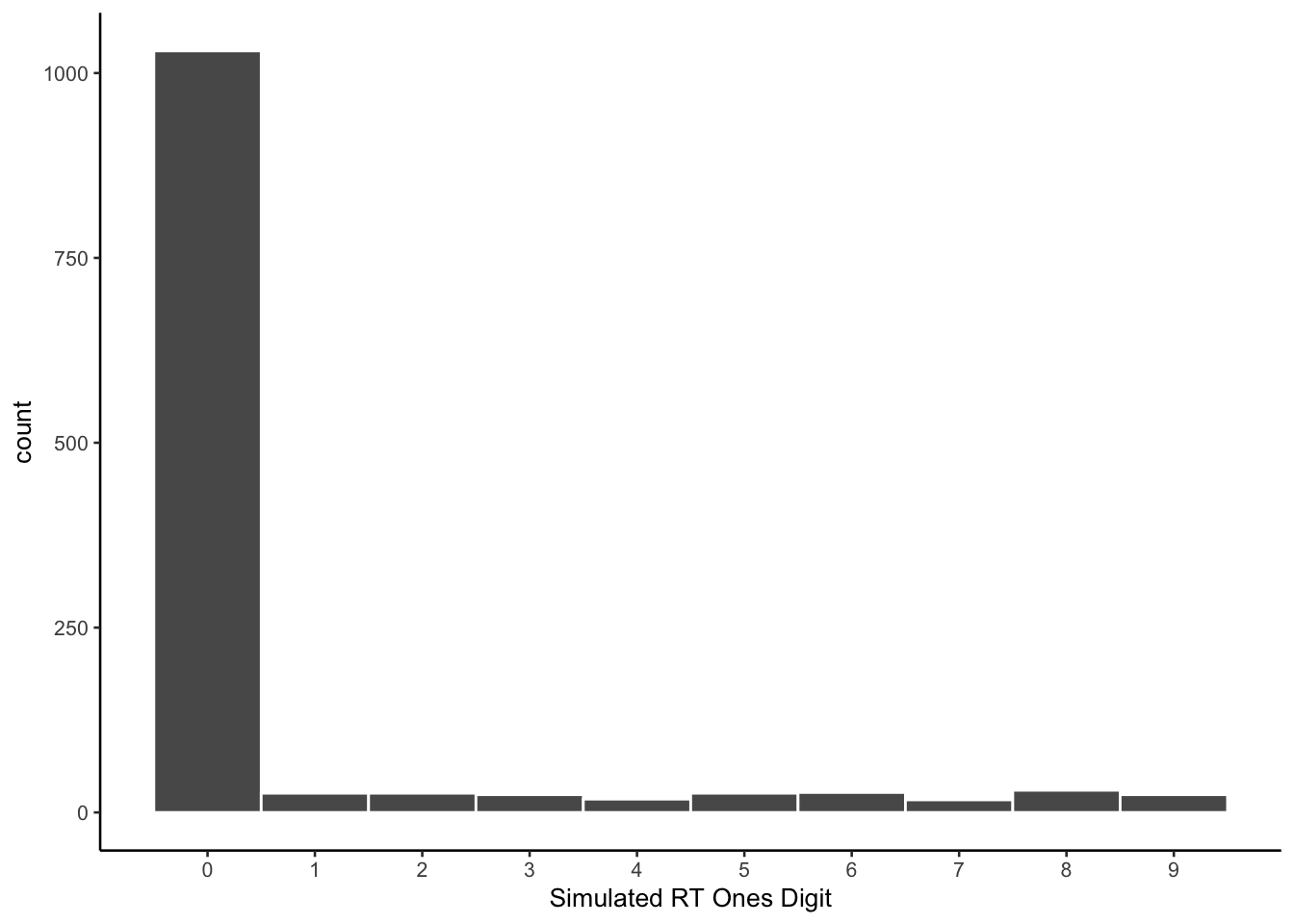
The model performs perfectly on congruent trials, and sometimes imperfectly on incongruent trials.
# report accuracy data
accuracy_data_subject <- all_sim_data %>%
mutate(congruency = case_when(word == color ~ "congruent",
word != color ~ "incongruent")) %>%
mutate(accuracy = case_when(response == color ~ TRUE,
response != color ~ FALSE)) %>%
group_by(congruency,sim_subject) %>%
summarize(proportion_correct = mean(accuracy), .groups = "drop")
ggplot(accuracy_data_subject, aes(x = congruency,
y = proportion_correct))+
geom_violin()+
stat_summary(fun = "mean",
geom = "crossbar",
color = "red")+
geom_point()+
theme_classic(base_size=15)+
ylab("Simulated Proportion Correct")+
xlab("Congruency")
This simulation used GPT-3.5-turbo-16k, and a slightly different prompt strategy. The model successfully returned valid JSON 28 out of 30 simulations.
One half of the simulated subjects received a list of 48 Stroop items that was 75% congruent. The other half received a list of 48 Stroop items that was 25% congruent. The model was not given any information about the proportion congruent manipulation in the prompt.
The results appear to show a larger Stroop effect for the high then low proportion congruent condition, which is the same finding consistently reported in the human cognition literature. I did not attempt to replicate this result with the model, and it is not clear if the model would consistently reproduce this result over several iterations.