Interim Overview
Matthew J. C. Crump 
This project and summary are works in progress and may be subject to changes until the project is completed.
Motivation: Why am I doing this?
I’m not prepared to flesh this section out today, so it is a promise for the future. I developed some of the motivation for this project in a blog post:
https://crumplab.com/blog/771_GPT_Stroop/
Elements of the motivation include:
Personal curiosity and an excuse to try programmatically interacting with the OpenAI API.
General concerns about LLMs being used to spoof human data in online situations, such as recent reports that MTurk workers are using LLMs to respond to HITs. I’ve noticed similar behavior in some of my own MTurk requests.
Wondering whether an LLM could fake data in the tasks I typically run online. These tasks are usually programmed in JsPsych and require speeded identification responses on a trial-by-trial basis.
What is this project?
In this project I am asking general questions about whether large language models, such as OpenAI’s gpt-3.5-turbo, can spoof human-like data in attention and performance tasks. The simulations so far use a text-based version of the Stroop task.
The figure below shows examples of Stroop stimuli that might be presented to people. The task typically involves naming the ink color of the word and avoiding naming the actual word. Responses are usually faster for congruent items, where the color matches the word, compared to incongruent item types, where the color mismatches the word.
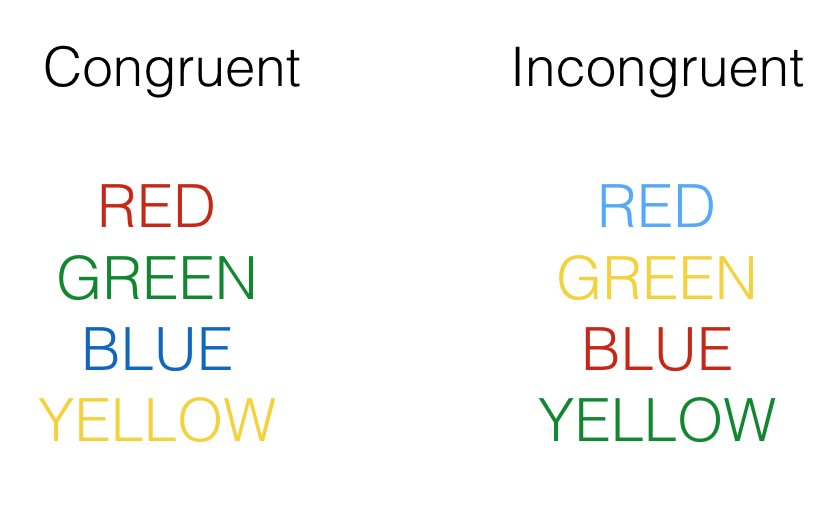
The general question for this project was, what happens if I ask a GPT model to perform a Stroop task?
I’m using a number of tools that greatly facilitate my ability to ask this kind of question. These include R, an R library for interfacing with the OpenAI API, and the ability of GPT models to return their responses in JSON (most of the time), which makes it easy to analyze simulated responses in R.
The details of the simulations run so far can be found on their respective pages in the modeling section. The approach is basically to prompt the model that it is about to perform a Stroop task. I provide trial-by-trial text saying what kind of item is presented on each trial (e.g., the word blue is written in the color red), and I ask the model to identify the color, and provide a simulated reaction time in milliseconds.
What happened so far?
The TLDR is that GPT can spoof Stroop data in several ways, and even in some interesting ways. The prompts I used have tell-tale signs that the data was generated by an LLM. Sometimes prompt modifications change the simulated behavior, and sometimes they did not. Let’s review the simulations. All of the details for each simulation can be found in their respective pages in the modeling section.
Simulation 1: Basic Stroop
This simulation used a prompt like:
Consider the following trials of a Stroop task where you are supposed to identify the ink-color of the word as quickly and accurately as possible:
The word red printed in the color blue
The word red printed in the color green
The word red printed in the color yellow
…etc. for 24 trials.
This is a simulated Stroop task. You will be shown a Stroop item in the form of a sentence. The sentence will describe a word presented in a particular ink-color. Your task is to identify the ink-color of the word as quickly and accurately as possible. Put the simulated identification response and reaction time into a JSON array using this format: [{“trial”: “trial number, integer”, “word”: “the name of the word, string”,“color”: “the color of the word, string”,“response”: “the simulated identification response, string”,“reaction_time”: “the simulated reaction time, milliseconds an integer”}].
The model produced valid JSON files that I could read into R 23 out of 25 times. The simulated data is in the form of a data frame with responses and reaction times for every trial, for each simulated subject. I read the simulated data into R, then analysed the data to determine whether or not the LLM would produce a Stroop effect. Specifically, would it generate fake reaction times that were on average faster for congruent than incongruent trials?
The answer is yes, these are the results from the model. In addition to simulating faster mean reaction times for congruent than incongruent items, it also produced different results for each simulated subject. These aspects of the data were not explicitly prompted, or at least I didn’t think I explicitly prompted them.
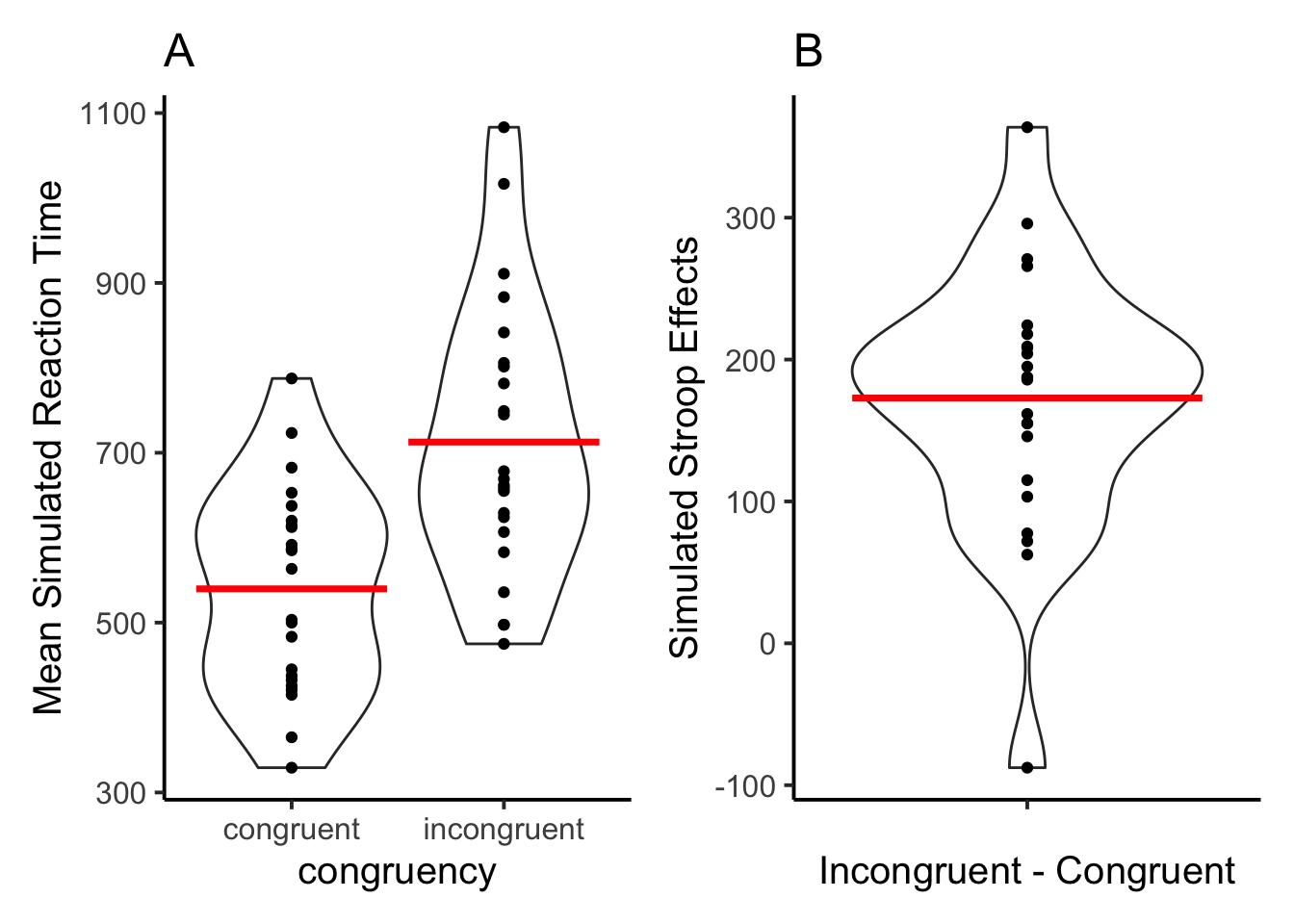
The model also generated really unrealistic numbers for reaction times at the level of individual trials. Almost all of the numbers were too rounded, as they ended in 0 or 5, mostly 0. Additionally, the model achieved 100% accuracy on all trials.
A curious finding was that the model also produced a congruency sequence effect. A common finding in the Stroop literature is that Stroop effects are larger following congruent trials than incongruent trials. Information about this phenomenon was not included in the prompt. Nevertheless, when I analyzed the data for the effect, it showed up.

It’s possible that this is a spurious finding, I don’t know. The lack of computational reproducibility in this kind of modeling work is very frustrating. It’s possible that the model was trained on raw data from human Stroop experiments, so when it produced data for this prompt, it used patterns that were available from the training set to generate simulated data. Or is that possible? I don’t know enough about how these models work to answer the question.
Simulation 2: Stroop instructions
This simulation includes some additional encouragement in the prompt to generate more realistic reaction times (not always ending in 0), and to make mistakes on some trials. Otherwise, it was similar to the first simulation. Again, it produces a Stroop effect with inter and intra-individual variability in reaction times.

This time the reaction times did not all end in 0, and collectively they even looked similar to human reaction time distributions (see simulation 2). The accuracy data was perfect for congruent trials, but mistakes were inserted on incongruent trials as instructed.
The take-home message was that changing the prompt did cause the model to produce reaction times and accuracy rates that conformed to the prompt instructions.
Simulations 3 to 6: Proportion congruent and refactoring the code for longer prompts
The first simulation showed that GPT generated both a typical Stroop effect and a congruency sequence effect, even though it wasn’t given information about how human performance depends on trial-to-trial aspects of the task.
The size of the Stroop effect is also known to depend on the relative proportion of congruent items in a list. The Stroop effect is typically larger for lists that contain a high proportion of congruent items compared to lists that contain a low proportion of congruent items.
Simulation 3 was similar to the first simulation, with one key difference. It involved providing certain simulated subjects a set of trials containing a high proportion of congruent items, while others received a set of trials with a low proportion of congruent items. However, this simulation encountered several problems, as it frequently generated invalid JSON that couldn’t be analyzed. One of the contributing factors was the excessive length and token usage in the prompt, surpassing the model’s allowable limit.
Simulations 4 and 5 were attempts to refactor the code to allow for longer prompts that returned results that could be analyzed. Simulation 5 worked quite well, and the approach used there was also employed in simulation 6.
Simulation 6 gave some subjects a high proportion of congruent list items, and other subjects a low proportion of congruent list items. Interestingly, the model appeared to show the standard list-wide proportion congruent effect, even though the prompt mentioned nothing about this. The figure shows a larger simulated Stroop effect for the high proportion congruent conditions than the low proportion congruent conditions.
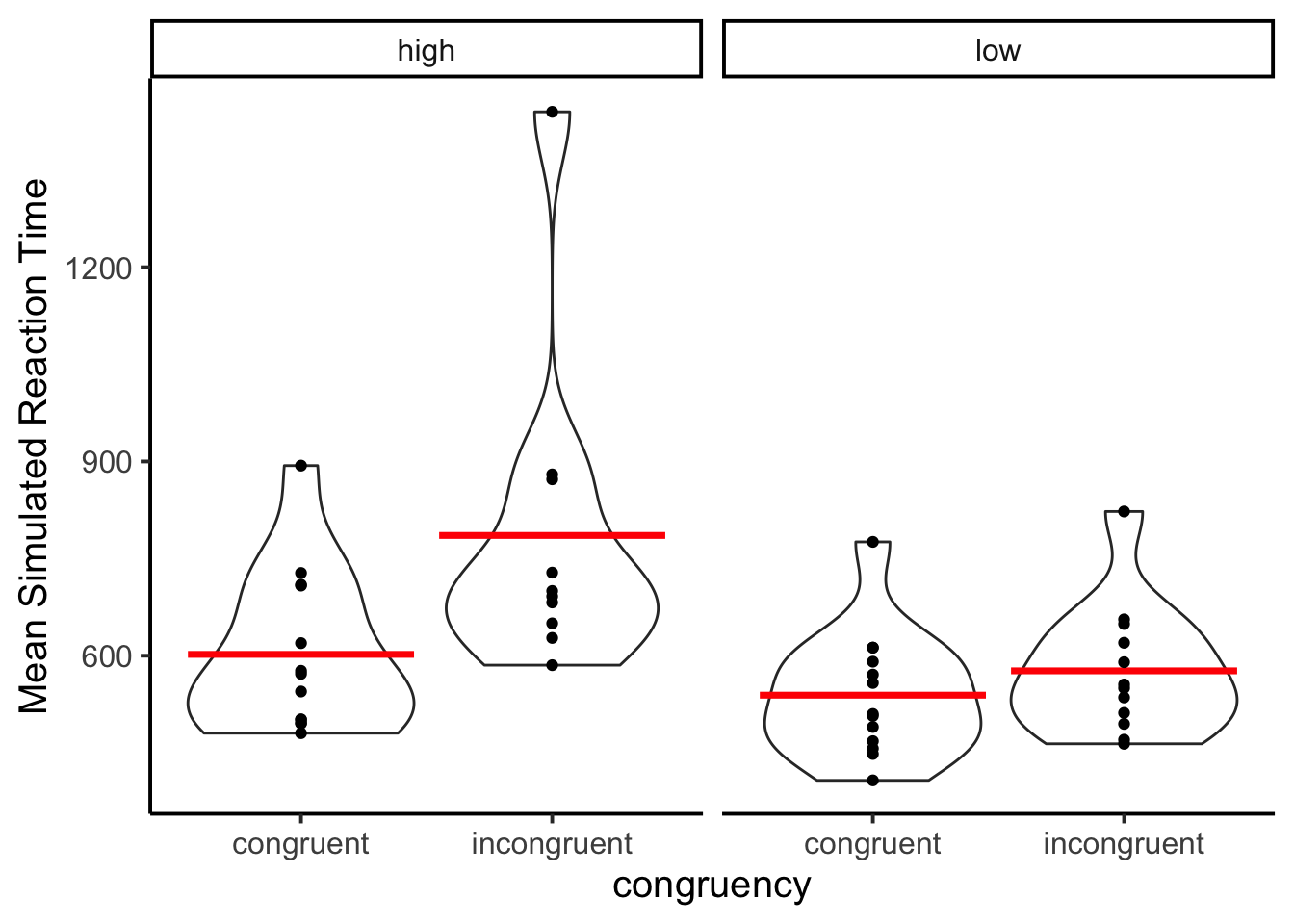
Simulation 7 and 8: Stroop Task-switching
I thought it was interesting that GPT produced a congruency sequence effect and a proportion congruent effect. I wondered how many other known effects it would produce in addition to the main Stroop effect, which is still very commonly observed in human data.
Simulation 7 involved a task-switching procedure. In each trial, the model was randomly prompted to identify either the color or the word from a Stroop stimulus. Typically, human participants would exhibit quicker word naming responses than color naming responses, along with exhibiting smaller Stroop effects on word naming trials compared to color naming trials. However, the model did not demonstrate faster word naming responses compared to color naming responses, nor did it generate smaller Stroop effects on word naming trials compared to color naming trials.
Humans typically show faster responses on task-repeat than task-switch trials. The model did not show this task switching effect either.
The figure shows the data from the model. The RTs for the identify word condition should have been much faster, and the difference between congruent and incongruent much smaller.
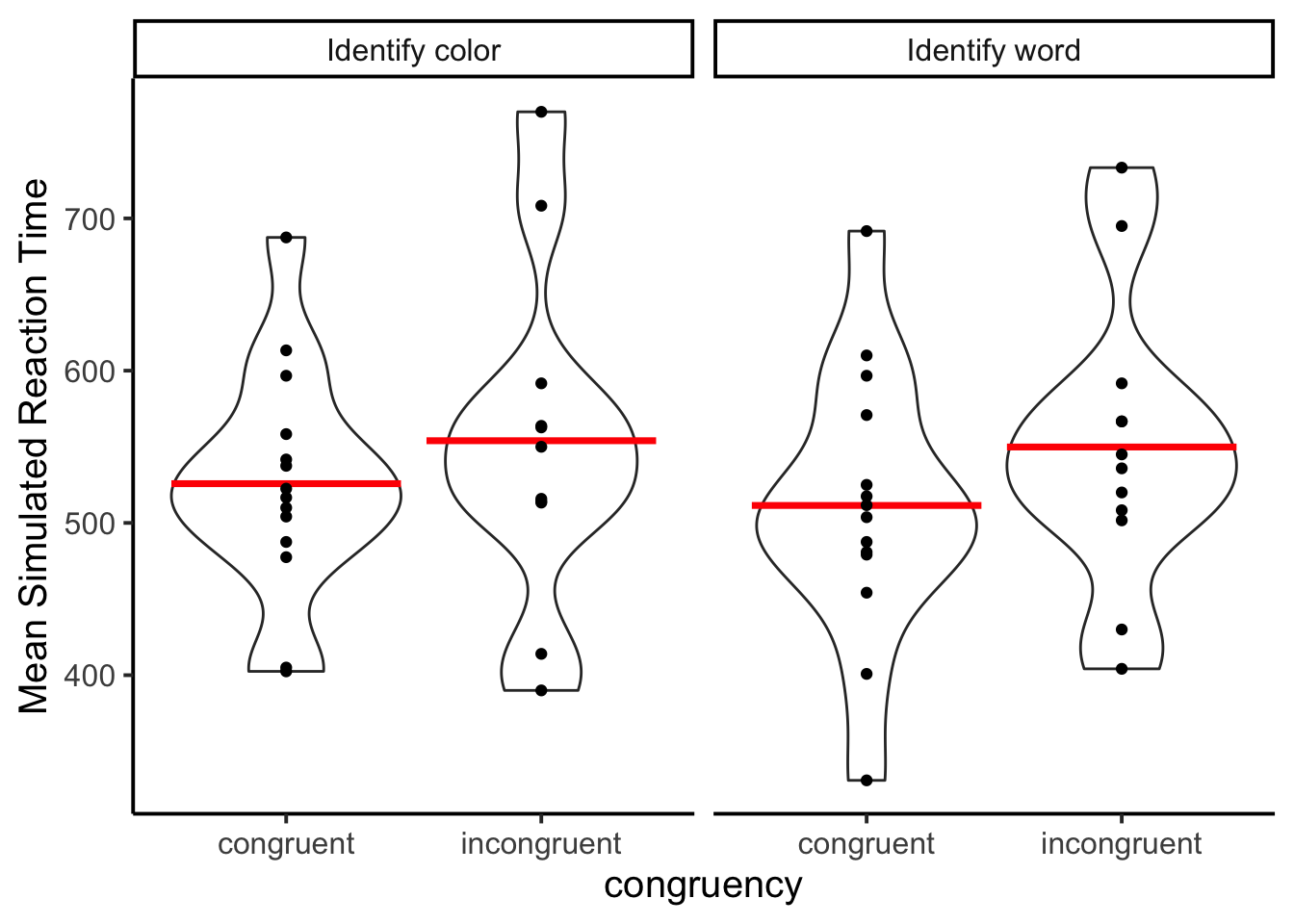
Simulation 8 repeated the previous simulation but gave prompts that were more explicit about how the model should behave. The relevant additions are in bold.
You are a simulated participant in a human cognition experiment. Complete the task as instructed and record your simulated responses in a JSON file. Your task is to simulate human performance in a word and color naming task. You will be given the task in the form a JSON object. The JSON object contains the word and color presented on each trial. Your task is to read the task instruction for each trial. If the instruction is to name the color, then identify the color as quickly and accurately as a human would. If the instruction is to name the word, then identify the word as quickly and accurately as a human would. Humans are much faster at naming words than colors. Humans show much larger Stroop effects for naming colors, and very small or nonexistent Stroop effects when naming words. When humans repeat the same task from trial to trial they are faster and more accurate compared to when they switch tasks from trial to trial. When you simulate data make sure it conforms to how humans would perform this task. The JSON object contains the symbol ? in locations where you will generate simulated responses. You will generate a simulated identification response, and a simulated reaction time for each trial. Put the simulated identification response and reaction time into a JSON array using this format…(see the code for details)
However, in this case, the explicit instructions didn’t seem to change the model’s simulated results. It showed no difference between color and word-naming. And, it didn’t show a task-switching effect either.