Show the code
library(tidyverse)
library(openai)
library(patchwork)
library(xtable)Matthew J. C. Crump 
Started Pilot data
Half-baked. Successfully ran 14 simulated subjects, but requested 20. May need to refactor the code to allow for longer prompts
See Simulation 6 instead.
Simulation one showed that GPT-3.5-Turbo can complete a Stroop task presented in the form of text prompts, and generate patterns of data that resemble human performance in several respects. For example, the model generated faster reaction times for congruent than incongruent items. The model generated reactions with inter and intra-subject variability. The model also performed with 100% accuracy, and chose implausibly round numbers. The second simulation varied the prompt to encourage more variability in accuracy and reaction time number generation. The reaction times appeared as if they were sampled from a continuous distribution. Accuracy rates for incongruent items varied across subjects.
In simulation 1 the model also generated reaction times that were consistent with congruency sequence effects. Specifically, the simulated Stroop effect from trials preceded by a congruent item was found to be larger than the Stroop effect from trials preceded by an incongruent item. The model was not given instructions regarding the congruency sequence, and it is somewhat intriguing that it generated data consistent with the presence of that effect. One possibility is that the models training corpus contains raw data from Stroop experiments, in which case it may be possible that the model generating data patterns for the present simulations in the style of existing training data.
I don’t know enough about how the model works, or the data it was trained on, to make strong claims or conclusions about these issues. Nevertheless, these issues are relevant to fleshing out concerns about using LLMs to spoof human data. In this case, the model appears to spoof multiple aspects of human performance in the Stroop task.
The purpose of the simulation 3 was to determine whether the model will generate data consistent with list-wide proportion congruent effects, without being prompted to do so.
library(tidyverse)
library(openai)
library(patchwork)
library(xtable)Notes: 20 simulated subjects. 32 Stroop trials each. First 10 subjects are given high proportion congruent, last 10 given low proportion congruent.
Unlike the previous simulations, each subject is given a different randomized order.
The new prompt is shown in the code.
Used default params for gpt-3.5-turbo from the openai library.
Problems: This code produced 14 valid JSON files out of 20.
# use the colors red, green, blue, and yellow
# four possible congruent items
congruent_items <- c("The word red printed in the color red",
"The word blue printed in the color blue",
"The word yellow printed in the color yellow",
"The word green printed in the color green")
# four possible incongruent items
incongruent_items <- c("The word red printed in the color blue",
"The word red printed in the color green",
"The word red printed in the color yellow",
"The word blue printed in the color red",
"The word blue printed in the color green",
"The word blue printed in the color yellow",
"The word yellow printed in the color red",
"The word yellow printed in the color blue",
"The word yellow printed in the color green",
"The word green printed in the color red",
"The word green printed in the color blue",
"The word green printed in the color yellow")
#set up variables to store data
all_sim_data <- tibble()
gpt_response_list <- list()
# request multiple subjects
# submit a query to open ai using the following prompt
# note: responses in JSON format are requested
for(i in 1:20){
print(i)
# generate 50% congruent and 50% incongruent trials
# 12 each (congruent and incongruent)
hpc_trials <- sample(c(rep(congruent_items,3*2),sample(incongruent_items,8)))
lpc_trials <- sample(c(rep(congruent_items,2),rep(incongruent_items,2)))
# choose proportion congruent based on subject number
if (i <= 10) {
trials <- hpc_trials
proportion_congruent <- "high"
} else {
trials <- lpc_trials
proportion_congruent <- "low"
}
gpt_response <- create_chat_completion(
model = "gpt-3.5-turbo",
messages = list(
list(
"role" = "system",
"content" = "You are a simulated participant in a human cognition experiment. Complete the task as instructed and record your simulated responses in a JSON file"),
list("role" = "assistant",
"content" = "OK, I am ready."),
list("role" = "user",
"content" = paste("Consider the following trials of a Stroop task where you are supposed to identify the ink-color of the word as quickly and accurately as possible.","-----", paste(1:32, trials, collapse="\n") , "-----",'This is a simulated Stroop task. You will be shown a Stroop item in the form of a sentence. The sentence will describe a word presented in a particular ink-color. Your task is to identify the ink-color of the word as quickly and accurately as a human participant would. Your simulated reaction times should look like real human data and end in different numbers. Put the simulated identification response and reaction time into a JSON array using this format: [{"trial": "trial number, integer", "word": "the name of the word, string","color": "the color of the word, string","response": "the simulated identification response, string","reaction_time": "the simulated reaction time, milliseconds an integer"}].', sep="\n")
)
)
)
# save the output from openai
gpt_response_list[[i]] <- gpt_response
# validate the JSON
test_JSON <- jsonlite::validate(gpt_response$choices$message.content)
# validation checks pass, write the simulated data to all_sim_data
if(test_JSON == TRUE){
sim_data <- jsonlite::fromJSON(gpt_response$choices$message.content)
if(sum(names(sim_data) == c("trial","word","color","response","reaction_time")) == 5) {
sim_data <- sim_data %>%
mutate(sim_subject = i,
proportion_congruent = proportion_congruent)
all_sim_data <- rbind(all_sim_data,sim_data)
}
}
}
# model responses are in JSON format
save.image("data/simulation_3.RData")load(file = "data/simulation_3.RData")The LLM occasionally returns invalid JSON. The simulation ran 20 times.
total_subjects <- length(unique(all_sim_data$sim_subject))There were 14 out of 20 valid simulated subjects.
This analysis has too few simulated subjects to be meaningful.
# get mean RTs in each condition for each subject
rt_data_subject_congruency <- all_sim_data %>%
mutate(congruency = case_when(word == color ~ "congruent",
word != color ~ "incongruent")) %>%
mutate(accuracy = case_when(response == color ~ TRUE,
response != color ~ FALSE)) %>%
filter(accuracy == TRUE) %>%
group_by(proportion_congruent,congruency,sim_subject) %>%
summarize(mean_rt = mean(reaction_time), .groups = "drop")
# make plots
ggplot(rt_data_subject_congruency, aes(x = congruency,
y = mean_rt))+
geom_violin()+
stat_summary(fun = "mean",
geom = "crossbar",
color = "red")+
geom_point()+
theme_classic(base_size=15)+
ylab("Mean Simulated Reaction Time") +
facet_wrap(~proportion_congruent)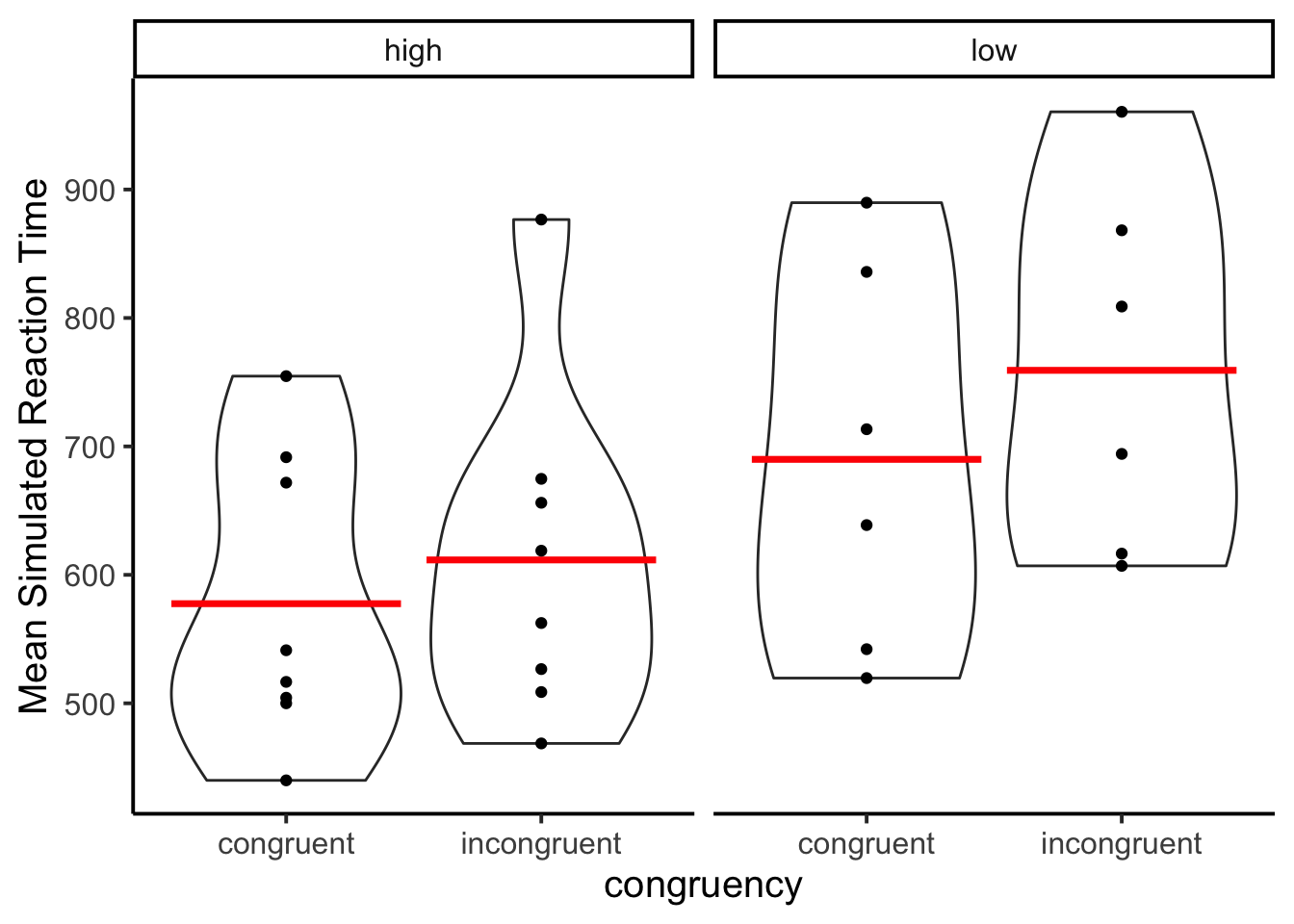
As with previous simulations, the reaction times look sort of Ex-Gaussian.
ggplot(all_sim_data, aes(x=reaction_time))+
geom_histogram(binwidth=50, color="white")+
theme_classic()+
xlab("Simulated Reaction Times")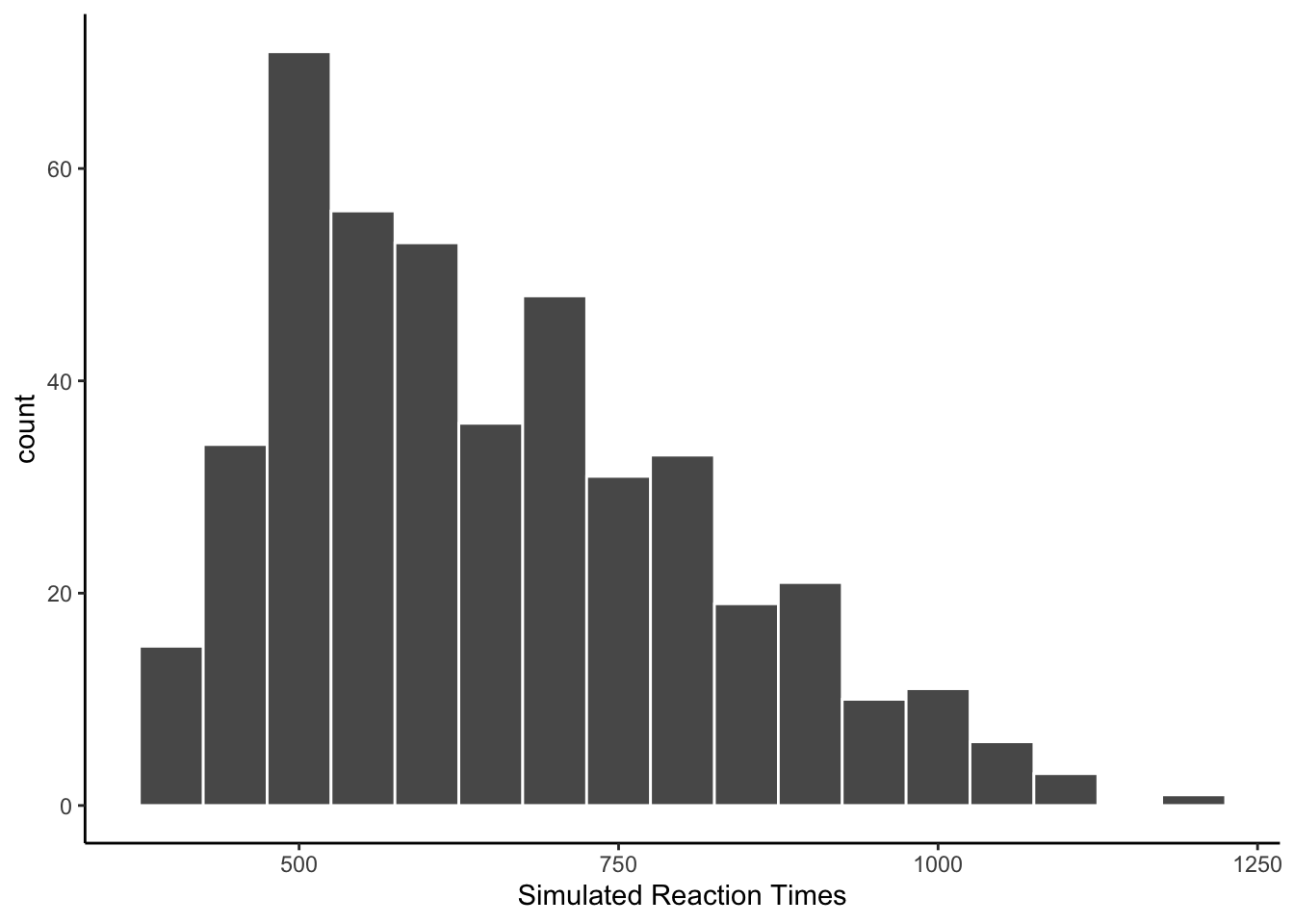
Setting the bin-wdith smaller shows that the model used many more numbers in between round intervals.
ggplot(all_sim_data, aes(x=reaction_time))+
geom_histogram(binwidth=10, color="white")+
scale_x_continuous(breaks=seq(250,1000,50))+
theme_classic(base_size = 10)+
xlab("Simulated Reaction Times")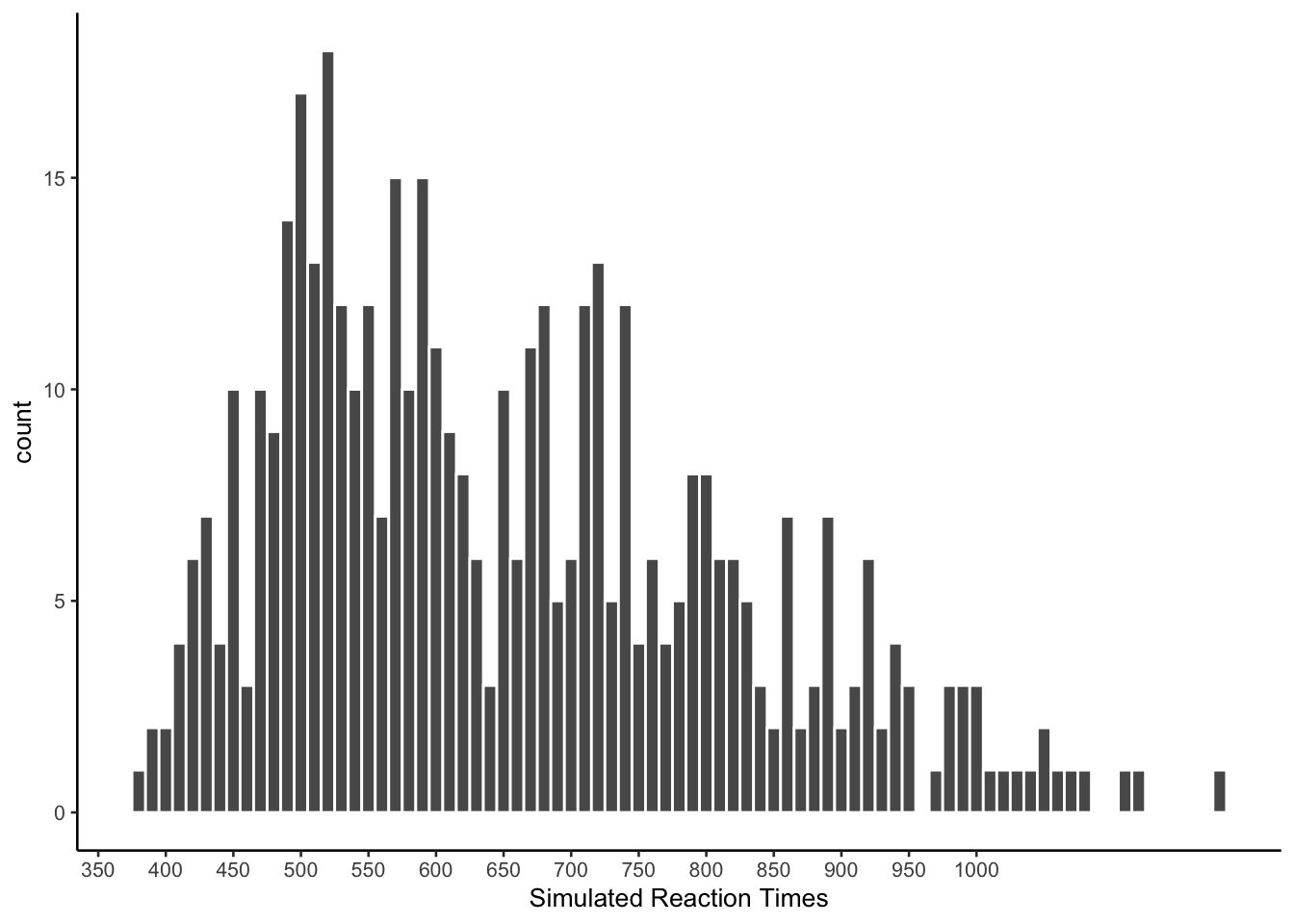
The model did produce simulated reaction times that ended in all possible digits. At the same time, it shows a preference for values ending in zero.
all_sim_data <- all_sim_data %>%
mutate(ending_digit = stringr::str_extract(all_sim_data$reaction_time, "\\d$")) %>%
mutate(ending_digit = as.numeric(ending_digit))
ggplot(all_sim_data, aes(x=ending_digit))+
geom_histogram(binwidth=1, color="white")+
scale_x_continuous(breaks=seq(0,9,1))+
theme_classic(base_size = 10)+
xlab("Simulated RT Ones Digit")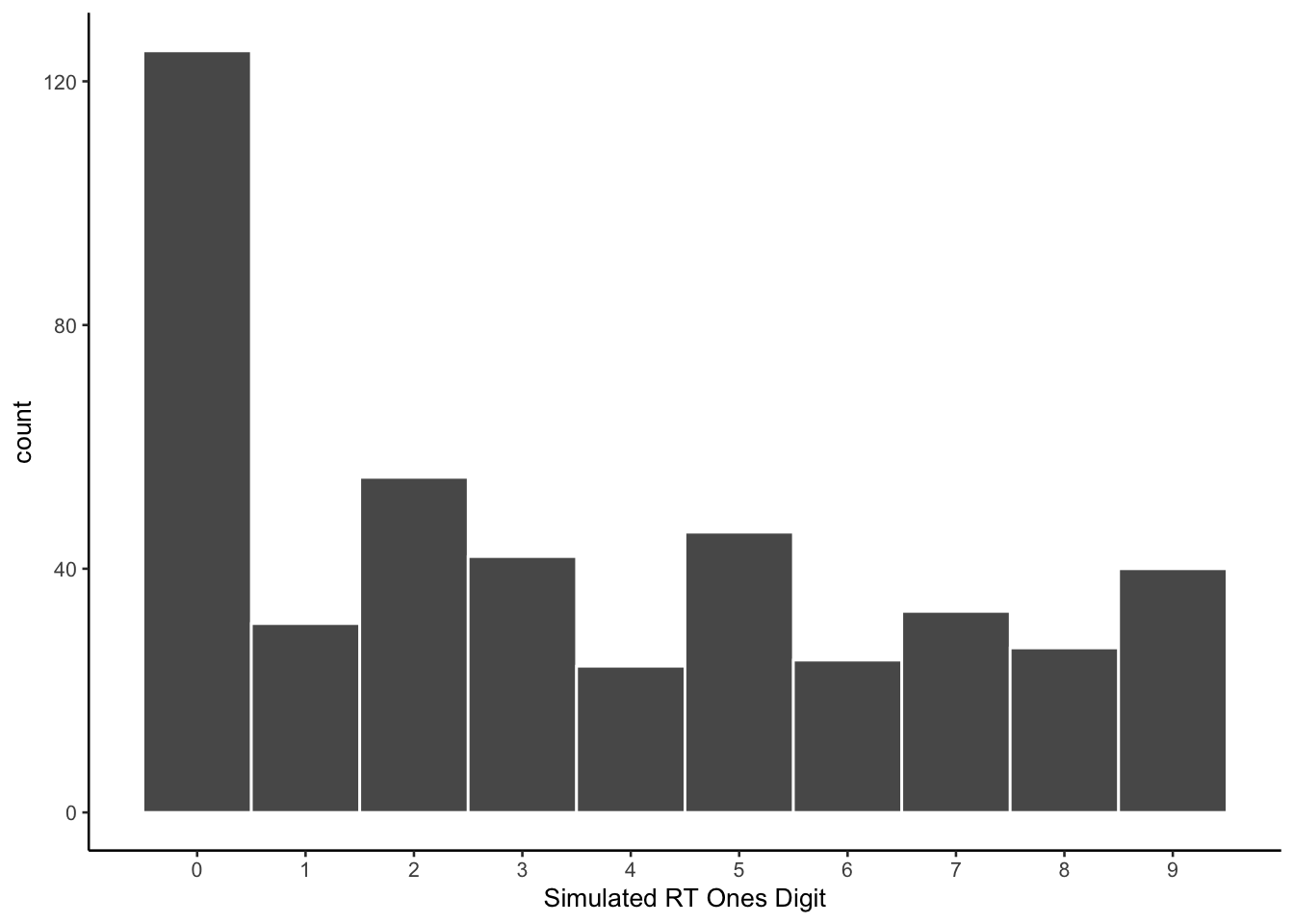
# report accuracy data
accuracy_data_subject <- all_sim_data %>%
mutate(congruency = case_when(word == color ~ "congruent",
word != color ~ "incongruent")) %>%
mutate(accuracy = case_when(response == color ~ TRUE,
response != color ~ FALSE)) %>%
group_by(congruency,sim_subject) %>%
summarize(proportion_correct = mean(accuracy), .groups = "drop")
ggplot(accuracy_data_subject, aes(x = congruency,
y = proportion_correct))+
geom_violin()+
stat_summary(fun = "mean",
geom = "crossbar",
color = "red")+
geom_point()+
theme_classic(base_size=15)+
ylab("Simulated Proportion Correct")+
xlab("Congruency")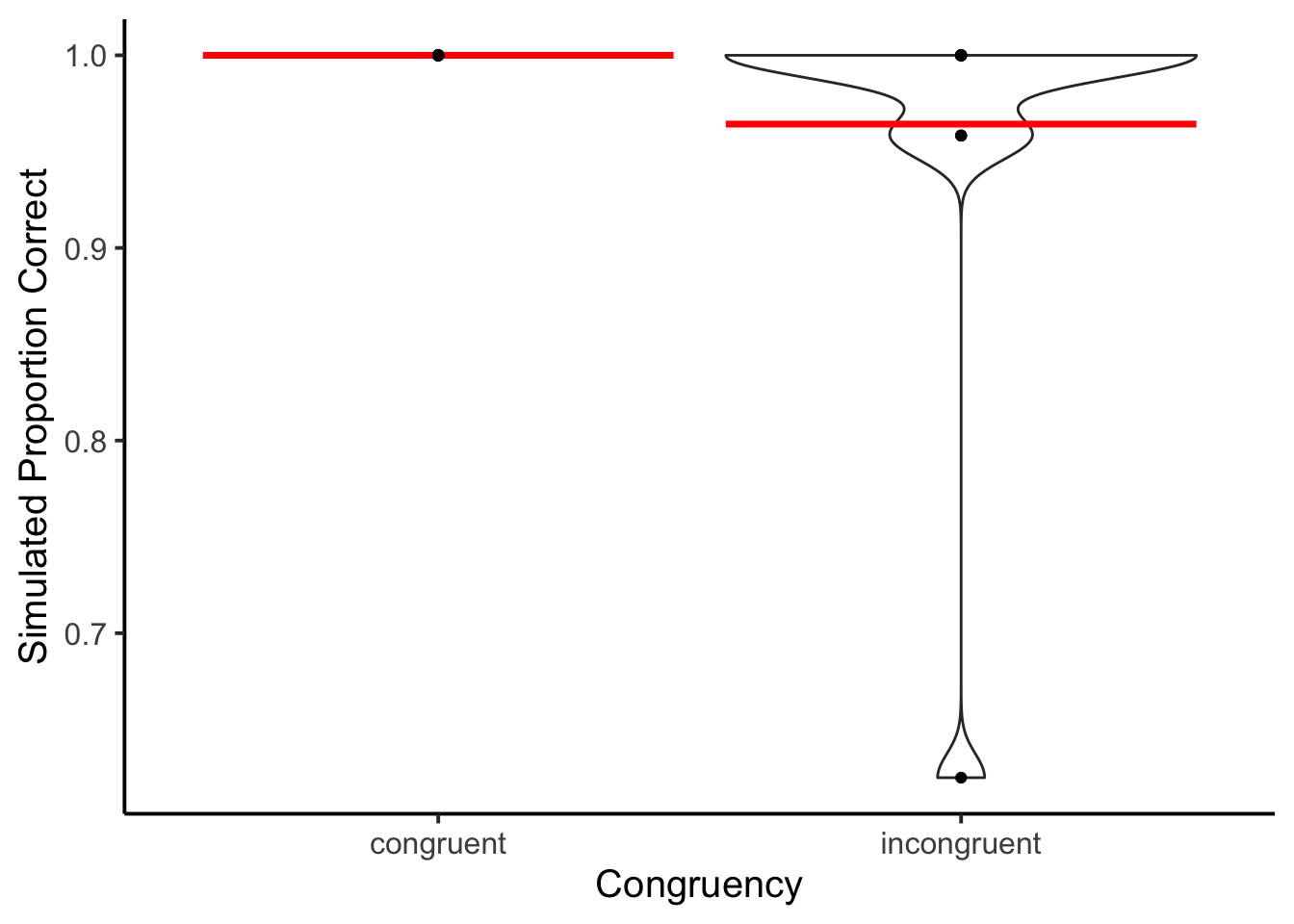
This simulation used a slightly longer prompt than the first two simulation. The first two simulations had 24 simulated trials, and this one had 32. I also tried a version with 48 trials per subject, but received 502 gateway errors from the API. I’m not sure whether the prompt was too long, or the expected response was too long.